The original visualization made use of data from the Imperial College London YouGov Covid 19 Behaviour Tracker Data Hub hosted at Github, and is appended below:
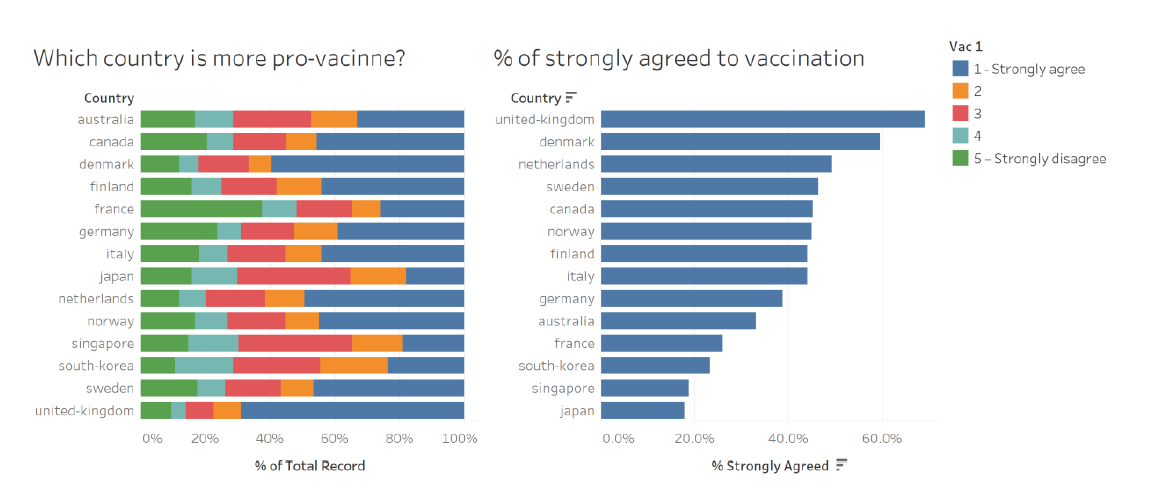
Section A: Critique of Original Viz
This section provides a critique of the original visualization and comments on both clarity and aesthetic aspects that could be further improved on. A total of 10 clarity issues and 8 aesthetic issues were identified.
Clarity
| S/N | Issue | Comments |
|---|---|---|
| 1 | Title (of 100% Bar Chart) | Title asked a question with no obvious answer provided from the visualization - at a first glance, this title created more questions than answer - after looking at the viz, we are still unclear which country is more “pro-vaccine”. This is partly due to issue S/n 2 and S/n 3 discussed below. |
| 2 | Sort Order (for 100% Bar Chart) | The main drawback of the visualization is the lack of meaningful sort (which is presented in an alphabetical order). In this case, viewers will need to visually seek out the country with the longest blue bar in order to make meaningful deduction (assuming only the blue bars are of interest to the viz-maker - which leads to the next issue) |
| 3 | Missing Survey Question | This is another major flaw of the visualization - there is no way of knowing what was the question that respondents strongly agree or disagree to even if we know what each color is referring to. |
| 4 | Incomplete Information on Data Representation | The legend does not give any description for the values 2 (orange), 3 (red), and 4 (light blue). It does not clearly reflect that the segments are ordinal (i.e. in order of any significance) and hence confusion on the interpretation of the viz. |
| 5 | Missing Definition for Survey Responses | Relatedly, while the titular question asked which country is more pro-vaccination, there is no clear indication of which color segment constitutes the “pro-vaccine” population (i.e. should we count the orange bar? What about the red bar?). |
| 6 | Ambiguous Unit of Measure | “% of Total Record” does not sufficiently explain what the base of the “%” is, and what constitutes the “Total Record” (which seems to be a variable name) |
| 7 | Meaningless Headers in Legend | Similar to Issue 4 above, “Vac 1” does not explain what question the response was for and is as meaningless as putting any random symbol. In fact, it creates even more confusion (especially since the actual survey question is no where in sight) - is the question asking whether respondents are willing to take only one (and not two) vaccine shots? Or perhaps, take it only after 1 year? |
| 8 | Redundancy of the Bar Chart on the Right | After diving deeper into the viz, it not difficult to realize that the right-hand viz is a repetition of the blue bars in the left-hand viz (except it is sorted by length of the blue bar) |
| 9 | Misleading Viz without Uncertainty | As a survey response, it is unclear how certain the visualizer is in the data (in the sense of statistical certainty) - it would be more helpful if the viz is presented with the error margins for various confidence interval presented |
| 10 | Missing Sample Size Info | In similar vein to the issue above, It is not clear if all the country has equal number of respondents, which could present a biased viz using percentage information. |
Aesthetic
| S/N | Issue | Comments |
|---|---|---|
| 1 | No Clear Color Transition | Color chosen for the ordinal scale is arbitrary and does not show any reflect any meaningful representation of the response scale, nor do they aid in answering the titular question. In fact there is even a repetition of blue (dark for 1, light for 4) for responses that are very different |
| 2 | Placement of Legend | While the legend is applicable for both charts, it is more applicable for the visualization on the right. However, the placement of it on the right panel of the viz requires viewers to glaze across the right-hand viz to extract information (however limited it is) from the land-hand viz to the legend |
| 3 | Inconsistent Order | While both the left- and right-hand viz are sending similar message, the fact that they are sorted differently makes them aesthetically irritable (and no less confusing - as covered in S/n 2 in Clarity section above) |
| 4 | Choice of Viz | Using bar chart to depict percentage of population that strongly agree to vaccination takes up unnecessary data ink (in addition to being inefficient in depicting accurate info with uncertainty - as discussed in S/n 9 in Clarity section) |
| 5 | Sloppy text | Using ‘%’ instead of spelling percentage out makes the viz unprofessional and reeks of sloppiness |
| 6 | Improper Spelling of Proper Noun | The issue above is exacerbated by the fact that country names are spelled without capitalizing the initial letter, as with the norm for proper nouns |
| 7 | Typo Error | Furthermore, spelling mistakes (“vacinne”) were spotted in the most obvious location - the title |
| 8 | Inconsistent Decimal Placing | The two visualizations also bore differing decimal points for the common X-axis |
Section B: Suggested Improvement
This section provides some suggested improvements that could be implemented to resolve issues discussed in Section A.
Clarity
| S/N | Issue | Suggested Improvements |
|---|---|---|
| 1 | Title | Ensure that a proper title that is reflective of the viz is given, If the title is providing answer to a question, the answer should be easily identified / obvious from the viz. Proper subtitle could also be given to provide more information on the viz (e.g. the original survey question that was asked, the year in which the survey was conducted etc.) |
| 2 | Sort Order | When there is an ordinal variable of interest (in this case, responses that are pro-vaccination) involved in the visualization, proper sorting of the variable of interest should be done in ascending or decscending order for ease of reference, especially in such cases where the categories does not have inherent rank/order (i.e. countries, as opposed to, say, age groups, which have inherent order). |
| 3 | Missing Survey Question | While the survey has solicited responses on a multitude of vaccination-related questions, the viz appears to only present response to one particular question (and without even providing the question in the viz). The existing viz can be improved by firstly presenting the questions to which the responses are visualized, and secondly to allow interactive toggling of different questions to see how various countries responded differently for the different questions |
| 4 | Incomplete Information on Data Representation | While the codebook itself does not specify the corresponding meaning for each of the value, common norm for similar 5-class Likert Scale survey response could be adopted (i.e. Strongly Agree, Agree, Neutral, Disagree, Strongly Disagree). At the very least, the viz should be consistent - if 2,3, and 4 are presented without qualitative description, the description for 1 and 5 should be removed as well. |
| 5 | Missing Definition for Survey Response | If there is no proper definition to define who are exactly “pro-vaccination”, viz-maker should make an effort to provide a definition to reduce ambiguity in the viz presented (one may argue that only those who strongly agree to the question that they will vaccinate themselves as “pro” vaccination, while others may argue that even those who sits on the fence, i.e. neutral, are not “anti” and hence pro-vaccination). As much as possible, the title should be non-controversial and presents matter-of-facts to prevent confusion. |
| 6 | Ambiguous Unit of Measure | To provide clarity on the data being presented, axes should clearly indicate the unit of measure and explain/present the base for which the measure is measuring - not simply leaving the auto-generated axis header with variable names as it is |
| 7 | Meaningless Headers in Legend | Header, if any, should be clear, and enhance the comprehension for the legend, not confusion. Otherwise, it might be better to do without any header |
| 8 | Redundancy of the Bar Chart on the Right | An additional chart should provide additional information and not just repeat what is already interpretable from another chart, even if it is to highlight certain aspect of the other chart (which could be achieved with other means). At the very least, the second viz should have a synchronised axis with the first if they are presenting on similar data to prevent confusion. |
| 9 | Misleading Viz without Uncertainty | A better improved version would be to plot an uncertainty visualization using dots-and-lines, with the dot representing proportion for the sub-population (in this case country), and lines (“wings”) extending out to reflect the uncertainty involved. This would give a more accurate depiction of the data presented without misleading with missing uncertainty information. |
| 10 | Missing Sample Size Info | Additional information could be included to provide a clearer broad picture of the data used (e.g. sample size, confidence interval for different confidence level) to give viewer a more informative and accurate understading of the data |
| 11 | Additional Enhancement | Beyond the improvements to be made in view of the issues discussed, the dataset provided also included various other questions that could be of relevance to answering the question of “which country is most pro-vaccine”, as well as having the potential to distill further insights from a demographical breakdown using an interactive visualization. Hence, relevant response results as well as socio-economic data could be incorporated as parameters or filters to allow deeper understanding of the data to better meet the objective of the viz. |
Aesthetic
| S/N | Issue | Suggested Improvements |
|---|---|---|
| 1 | No Clear Color Transition | Color chosen for the ordinal scale should be reflective of the response (e.g. transit from darker/brigter to lighter/muted shades of the same color for differing degrees of response such as between Strongly Agree and Agree; and have contrasting color for positive and negative responses such as red for disagree and blue for agree in this case) |
| 2 | Placement of Legend | Legend should be positioned for ease of reference |
| 3 | Inconsistent Order | Sorting conventions (e.g. for non-ordered/ranked categories, don’t have to keep to existing order, e,g, alphabetical, if the variable of interest has an ascending/descending order) should be followed for ease of reference and prevent aesthetically unpleasing jagged viz in the different colored bars |
| 4 | Choice of Viz | data ink should be optimised (while not losing clarity) as much as possible with good choice of visualization |
| 5 | Sloppy text | Proper spelling of fucntions, names, and variabales should be used to present viz professionally |
| 6 | Improper Spelling of Proper Noun | Efforts could be made to edit presentation and adopt proper English conventions for spelling |
| 7 | Typo Error | Typo error should be avoided and vetting should be done before publishing |
| 8 | Inconsistent Decimal Placing | Decimal Placing should be consistent especially if similar data drawing from the same variable is being used |
Discussion on Likert Scale Visualization
The visualization on the left is essentially a basic Likert Scale visualization using a 100% Stacked Bar. In what is now a classic debate in the data visualization realm, Stephen Few, in his 2016 blogpost, countered Cole Nussbaumer Knafic’s preference for a 100% Stacked Bars, and proposed alternative visualizations to achieve different objectives. He argued that "variations on the design of 100% stacked bar graphs usually work better). For one, he recommended what is now known at Diverging Stacked Bars (negative values running left from zero and positive values running right from zero) with separate neutral bars. He argued that this allowed difference between positive and negative results to stand out more. For situations where neutral results are more appropriate to be incorporated in the same viz, he recommended for the results to run down the middle.
The proposals, especially the latter with neutral running down the middle, was met with resistance from Nussbaumer, expectantly. She argued that the neutral bars in the middle creates the illusion where results with long neutrals appear to be more positive than they really are, courtesy of a long neutral that pushes bars further in the positive and negative regions.
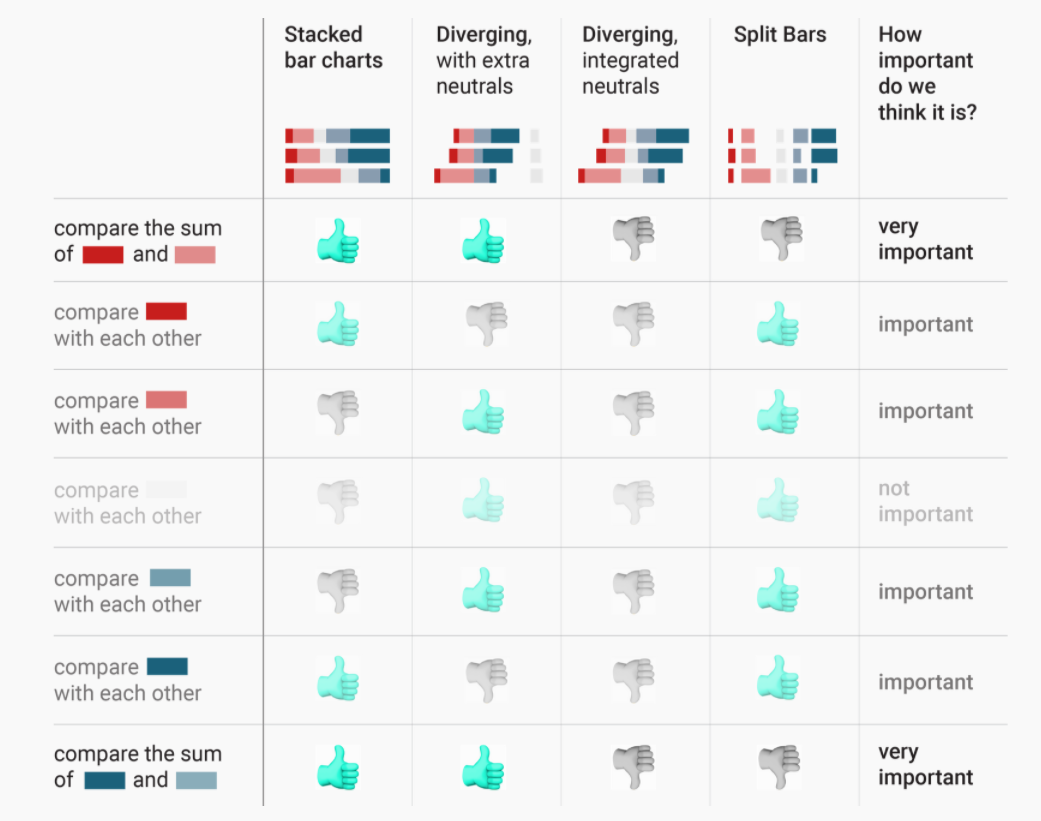
Nussbaumer was not the only one who disagreed. Lisa C. Rost & Gregor Aisch discussed two minor and one major shortcomings of the diverging stacked bars in their 2018 blogpost, in favour of the 100% stacked bar. Rost and Aisch argued based on the following three premises:
- The total agree & disagree shares are more important than the individual values of ‘strongly agree’ and ’agree
- Opinions are more important than non-opinions (“people who are undecided are kind of boring”)
- Including neutral percentages in the final chart is important (“‘Don’t know’ is data”)
Based on these premises, the authors argued that the divergent bar charts (1) loses intuitive understanding that parts within the stacked bars are shares, (2) is a waste of space, and (3) is hard to compare the length to either side of the middle line (and this is worse in the neutral-in-the-middle version). The authors also summarized the various viz options for Likert Scale data:
This was subsequently met with a response from Daniel Zvinca, who presented a solution with stronger views in the middle, advocating for a “butterfly-like” design, showing the most antagonist (i.e. strongest) values in the center. Daniel argued that this allows viewer to focus on what is most important (be it for policymakers or business owners to focus on who most agree/disagree with their product/service). He also argues that this solution addresses the weaknesses highlighted by Rost & Aisch.
Lastly, Daniel provided options for the treatment of the neutral values - depending on the target question in mind for the visualization to address, neutral bars can be split equally into two ends of the chart or to either end.
Based on the series of discussion/debate above, it is clear that 100% stacked bars and diverging stacked bars each have their pros and cons. For the purpose of this dataviz makeover, where the objective is to present survey responses to reflect proportion of population that are supportive of the use of vaccine versus those who are not. In this simplified problem statement (i.e. a dichotomy between pro and non-pro vacccine population), the Diverging Stacked Bar is preferred. Daniel’s version of placing stronger opinions in the middle provides a clearer distinction between two opposing camps of opinion - exactly apt for this viz’s objective.
In the treatment of neutrals, the author of this viz makeover agrees strongly with the premises laid out by Rost and Aisch, including the fact that neutrals will need to be included (though they are boring). This is especially important when we move on the discussion next on biasness and uncertainty. Of course, considerations were also made on the space constraints to incorporate two charts in one viz (more on that in next section), and neutrals, bring no more special than other non-pro response in this case, does not warrant a separate column on its own for special attention. In line with the principle to display stronger views in the middle, neutrals (being the least “strong”) will be pushed to the sides. In consideration of the dichotomy nature, though, it would be more appropriate for the neutrals in this viz to be on the negative end of the chart (i.e. the non-“pro” end) - ultimately, sitting on the fence for an issue definitely does not qualify one as being “pro” towards the issue.
A visualised concept of the proposed viz is presented by Daniel in his post and presented below:
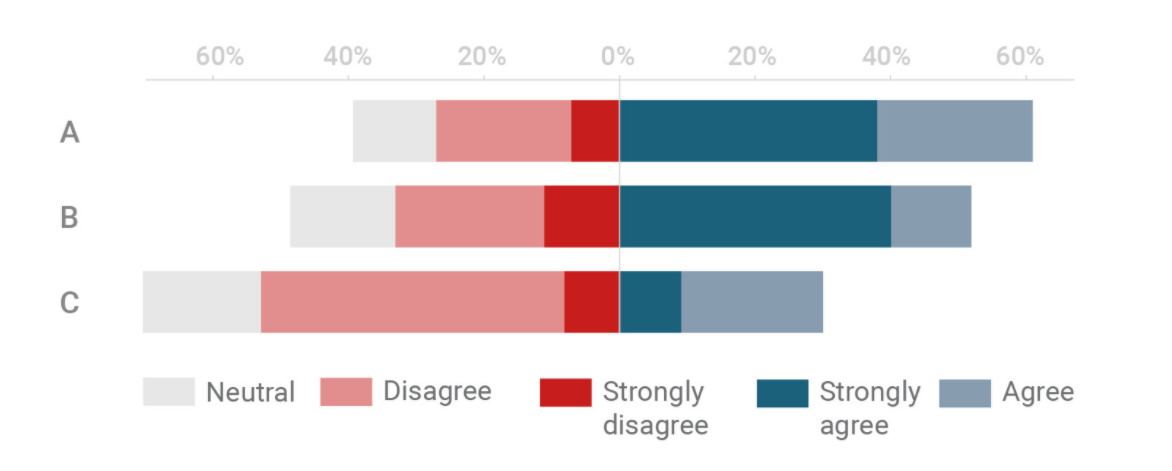
Referencing the summary table drawn up by Rost & Aisch, this version provides the advantages that a Stacked Bar Chart offers, preserves the 100% proportionality (i.e. all bars are of equal length summing to 100%), all while creating the contrast in the middle for visual distinction that is not present in the Stacked Bar Chart. Steve Wexler presents a step-by-step guide for the creation of a Diverging Stacked Bar, for which this viz references.
Discussion on Visualization of Uncertainty
Because of errors from random sampling, it is difficult to determine the exact value of the population mean from which the sample is drawn from using only information from the sample. However, it is possible to construct a set of values that contains the true mean with certain prespecified probability - this is referred to as the confidence interval. A 95% confidence interval, in lay terms, provides a range for which we are confident the true mean would fall within 95 times if we were to repeat the sampling 100 times.
When discussing survey response, it is critical to present the results with the uncertainty that comes along with sampling, lest we mislead viewers into thinking the sample results are definitive in representing the population at-large, and conclude more than the data allows. Visualization of uncertainty is also critical when we have different sample sizes across the categories we are comparing, and especially so for sub-categories where the sample sizes are small (and hence uncertainty are correspondingly huge) - without visualizing the uncertainty, viewers will be misled into concluding something based on only a small sample.
Nicole Torres discussed the difficulty in visualizing this uncertainty in a 2016 article - attributing the difficulty in the abstract nature of the uncertainty (Torres went on to also discuss the issue of interpretation - e.g. given a 90% chance of an event happening, even if it does not happen, it does not mean the prediction/viz is wrong; the unlikely just happened. But this is outside the scope of this blog post). Claus O. Wilke discussed this problem on the visualization of uncertainty in Chapter 16 of his book - Fundamentals of Data Visualization. In visualizing the uncertainty of point estimates (as is the case we want to make in this viz, for the proportion of respondents who are pro-vaccination - or whichever question is asked), Wilke presented several options, each with an identified strengths and weaknesses. Wilke explained that error bars with cap highlight the existence of different ranges corresponding to different confidence levels, but adds on visual noise.
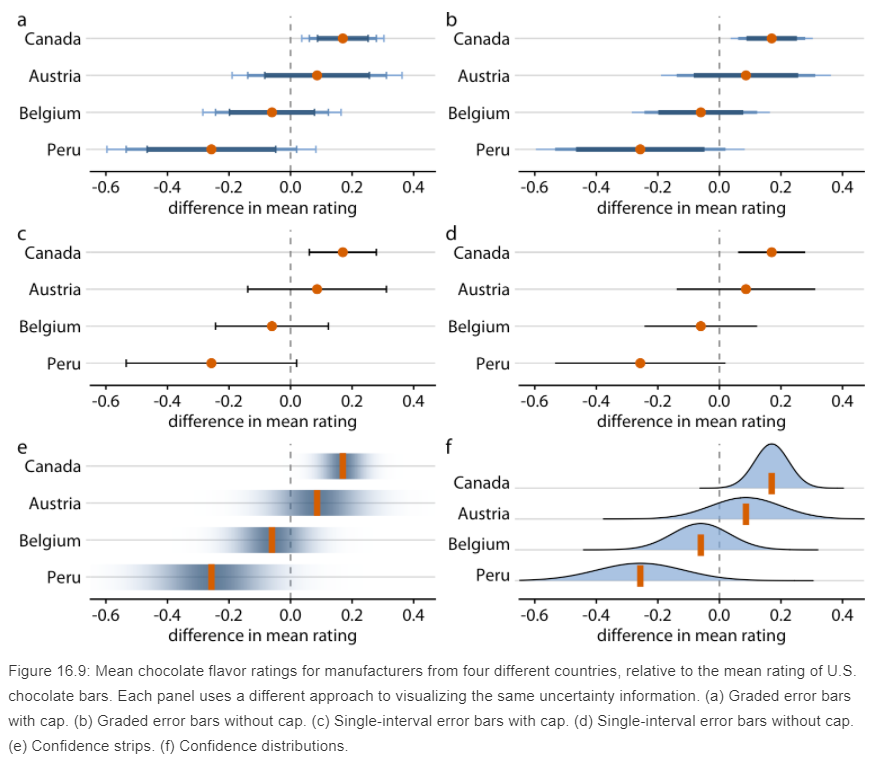
Steve Wexler, in another step-bystep guide in the visualization of error bars in Tableau, referencing Ben Jones’ book Communicating Data with Tableau. In this blogpost/guide, Wexler advocated for the dot-with-dual-error bars viz, while providing his comments to this eventual choice
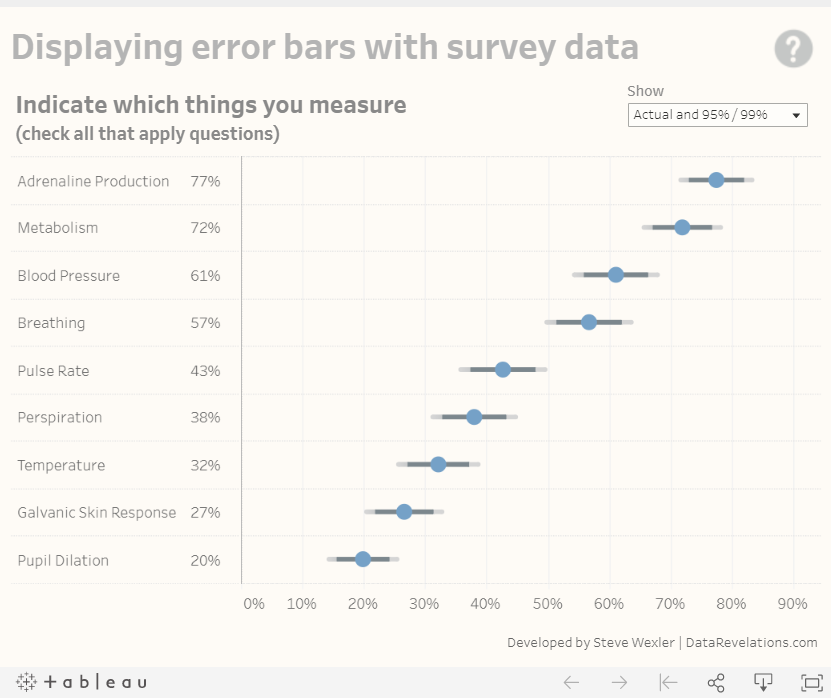
Wexler echoed Milke’s concerns that a cap line (‘whiskers’ at the end) gets too much attention than the dot and error lines themselves. He also presented a ‘fingernail’ chart, which he confessed to be ugly; a gradient bar for the confidence interval, which are cool but distracting; as well as a Gnatt error bars, which are similarly stole the limelight from the main dot point estimate.
Wexler concurred with Sönning’s views in his paper that prominent elements should receive more attention and hence decided on the final dot-with-error-bars (without whiskers) that we see above. The author of this visualization agrees with the need to ensure salient figures are given the attention they require and to reduce distractions to viewers. Wexlex’s step-by-step guide, as well as the Tableau workbook enbeded within, were used for the visualization of the dot-with-error-bars viz for this post.
Makeover Concept
Taking in the points discussed above, a redesigned visualization could look like the following:
Addressing Clarity Issue
| S/N | Issue | Ways in which proposed viz resolve issues identified |
|---|---|---|
| 1 | Title | This new viz provides clear title of what the question is asking, as well as some of the key info in the subtitle |
| 2 | Sort Order | A much interpretable viz with the countries having positive responses immediately identified with both charts |
| 3 | Missing Survey Question | Survey questions is included in prominence |
| 4 | Incomplete Information on Data Representation | Clear information provided on what each color means with proper placement of response value |
| 5 | Missing Definition for Survey Response | “Pro-vaccine” vs those who are not are clearly segregated into two sides of the “y-axis” to provide visual dichotomy to address the the objective of the viz - i.e. which country is more pro-vaccine. |
| 6 | Ambiguous Unit of Measure | Proper display on unit of measure to reduce ambiguity |
| 7 | Meaningless Headers in Legend | Since the responses are intiutive when presented together with the survey question as the title, a header is redundant and removed |
| 8 | Redundancy of the Bar Chart on the Right | Viz on the right is revamped to showcase the uncertainty involved in presenting the “pro” vaccination response, and hence, a different dimension to the viz with additional information - it is no longer redundant |
| 9 | Misleading Viz without Uncertainty | Viz on the right has addressed this issue to enhance clarity and accuracy |
| 10 | Missing Sample Size Info | Sample size info is provided for viewers to make informed deduction on the proportion of pro-vaccinators, where longer uncertainty error bars gives raises the alert for viewer to be cautious, and the records number provides another point of reference to pick out any red-flags. |
| 11 | Additional Enhancement | Enhancement in the form of filters and parameters to narrow down into particular sub-population is also added - this makes use of the inherent strength of tableau - allow user-friendly dashboards for users to toggle and explore the dataset to its full potential. Lastly, the visualizations are also optimized to tailor to the objective in mind, as discussed in the sub-segment above. |
Addressing Aethetic Issue
| S/N | Issue | Ways in which proposed viz resolve issues identified |
|---|---|---|
| 1 | No Clear Color Transition | Proper color transition and contrasts are incorporated to emphasize the distinction between those who are “pro” and those who are not, as well as to provide greater focus on stronger opinions. |
| 2 | Placement of Legend | Legend is placed at position easy for reference |
| 3 | Inconsistent Order | Bars are sorted to enhance clarity as well as in a visually-pleasant manner |
| 4 | Choice of Viz | data ink are optimized with the choice of viz that best presents the data while preserving (or even enhancing) clarity |
| 5 | Editorial Issues | Proper spelling of functions, names, and variables are used; English conventions adopted; typo vetted against; and consistency in formatting are in placed to ensure professionalism |
Section C: Redesigned Visualization
Using Tableau, the redesigned visualization based on the discussion points and concept presented in Section B above is created as follows:
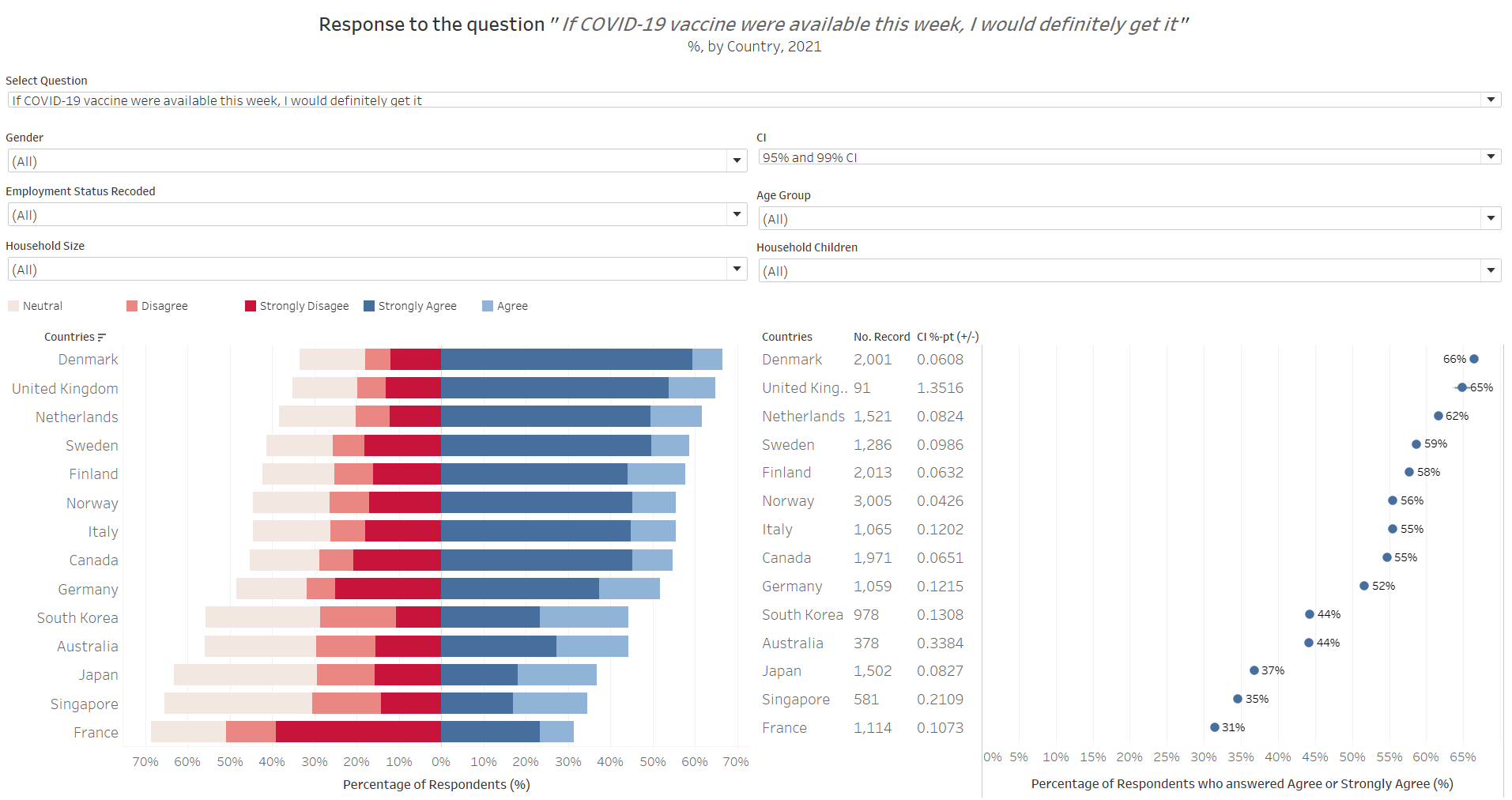
The redesigned visualization can also be accessed via this link
Section D: Step-by-Step for Viz Makeover
This section provides a step-by-step guide to recreate the redesgined visualization.
Part 1 - Data Preparation
Step 1.1 - Download and Import Data
First, download the data files used via this link to the Imperial College London YouGov Covid-19 Behaviour Tracker Data Hub.
As the data files are separated by the various countries for which the surveys are conducted, with some being zipped up in zip folders, we will next need to unzip these files. For the ease of data retrieval later on, we will store all the country files to be used in one common folder.
Thereafter, open Tableau Prep Builder to prepare for the data wrangling process.
Step 1.2 - Importing Mulitple CSV files
Drag-and-Drop one of the country file to be used onto the home page of Tableau Prep Builder. Under the ‘Input’ panel, select ‘Muiltple Files’, click on ‘Wildcard union’, then search in the folder where all the country files to be used are stored. Click ‘Apply’
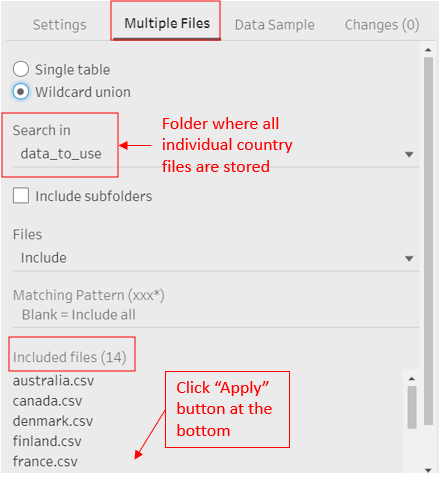
Step 1.3 - Filtering Relevant Data
Once all the datasets are joined, uncheck all fields then check on the box of the following relevant fields to select them for retention:
- Vac_1, vac2_1, vac2_2, vac2_3, vac2_6, vac_3
- endtime
- gender
- age
- employment_status, employment_status_1 through employment_status_7
- household_size, household_children
- File paths
Once that has been applied, we next filter the data to focus on records from Year 2021: click on the ‘Filter Value’ tab, and input the following calculation, then click Apply and Save
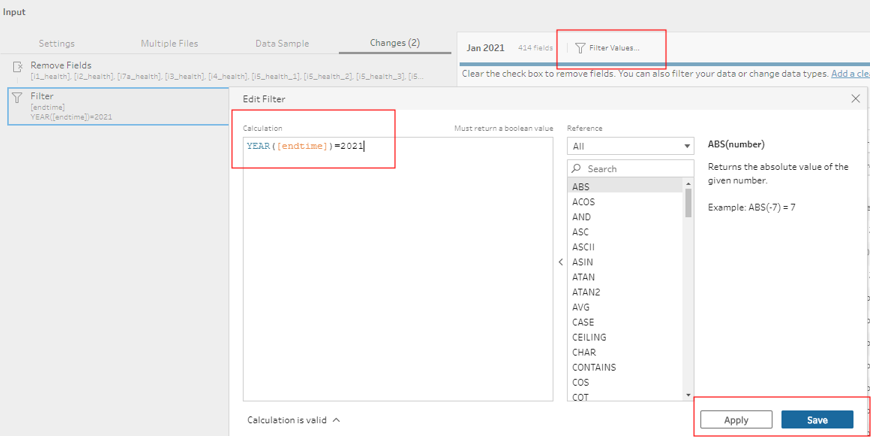
Step 1.4 - Data Issue: Pivoted Employment Fields
There are numerous data issue with the employment_status fields. Most obviously, Nordic countries Sweden, Denmark, Norway and Finland actually pivoted the employment_status field to form 7 different columns for each of the responses. The real problem, however, is that there are overlaps in positive responses to the 7 columns (i.e. they are not mutually exclusive - respondents could answer “Yes” to multiple employment status).
To resolve this issue, priority has to be devised to accord one prevailing status for rows with multiple Yes’s to the employment status. In this visualization, full-time employment will take precedence over any other status (i.e. if a respondent answers Yes to full-time employment, he/she will be recorded as having full-time employment under a recoded employment status column). Next piority, in order, will be for full-time student, then part-time employment (other status has no overlaps). The above logical recoding of the employment status field can be achieved by creating the following calculated field:
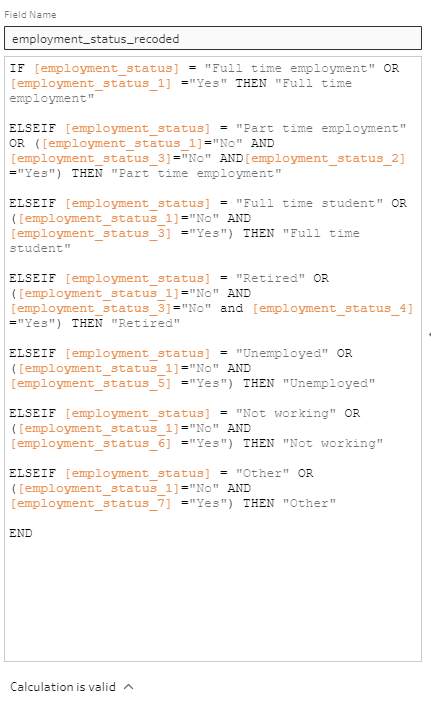
Step 1.5 - Renaming Fields and Values
Next, we rename the File Path variable to ‘Countries’, remove the ‘.csv’ at the end of each entry, then capitalize the country name for proper spelling of country names.
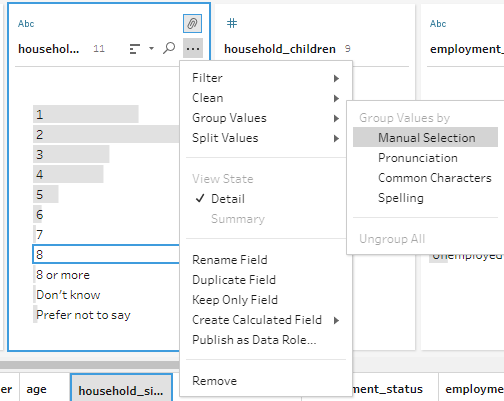
For the Household Size and Household Children fields we regroup all categories 8 and above as ‘8 or More’. ‘Don’t know’ and ‘Prefer not to say’ entries are recoded as null.
Step 1.6 - Output Data
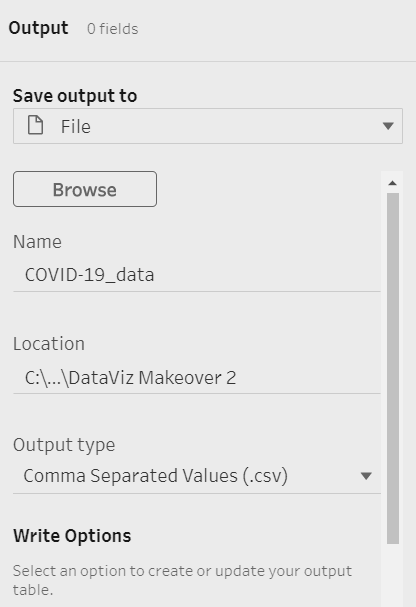
Finally, include an Output node on the Prep Building flow

Output the cleaned data as a csv file back to the folder where the datasets were stored, with the following options:
Part 2 - Creating Divergent Stacked Bar
Step 2.1 - Importing Data & Assigning Variable Types
First, open Tableau then import the merged and cleaned dataset by drag-and-dropping it onto the main page.
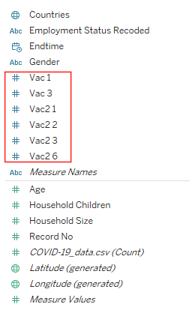
Tableau automatically assigns variables with integer values as Measures - this is not accurate for our survey response variables where 1 represents ‘Strongly Agree’ and 5 ‘Strongly Disagree’. Hence, we shift these vac_x variables from the Measures section to the Dimension section
Step 2.2 - Creating Variables for Stacked Bar
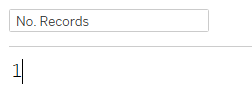
We start by assigning 1 to all entry and call it ‘No. Record’ - this will come in handy when we calculate the survey entries. Go to the “Analysis” tab at the top of the page, click on “Create Calculated Field…”, then input the following name and formula:
Next, we sum up the records count by creating the following new calculated field following the same steps as above:

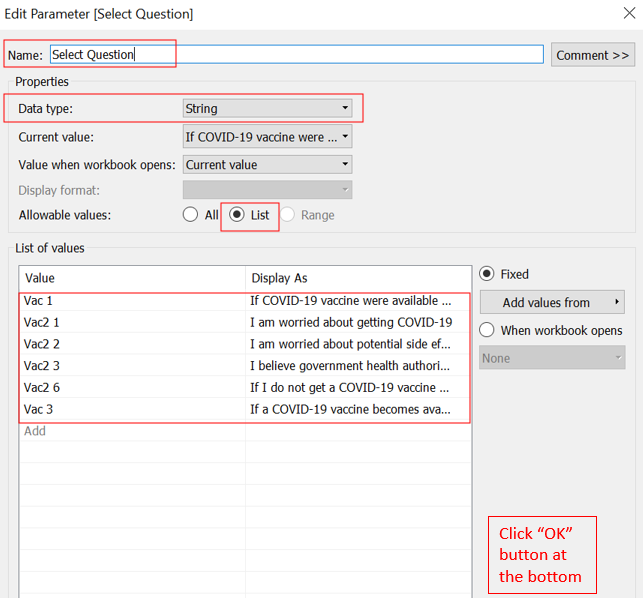
We will need a Parameter to toggle between the different questions we have included in the viz, soliciting user to select a question of interest. - Right click on an empty spot in the Data panel, select “Create Parameter…” from the list of options. - Rename the Parameter to “Select Question” - Data type as String - Check on “List” for “Allowable values” - Input the corresponding variable name for the different vaccination-related survey question that we have chosen to retain, then key in their corresponding full question under “Display As”.
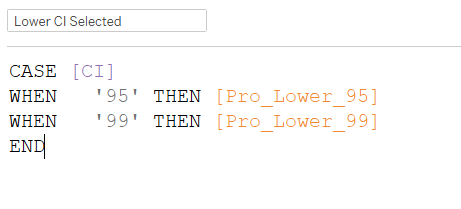
The Parameter will then need to be “activated” to trigger response to the viz: create a new calculated field (“Question Selected”) using the CASE function as below - when a parameter is selected, the corresponding “vac_x” variable will be called into view:
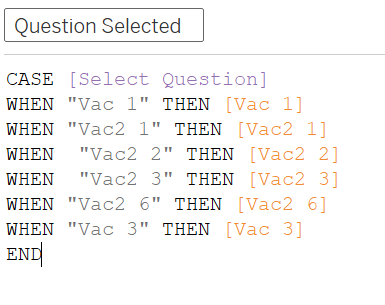
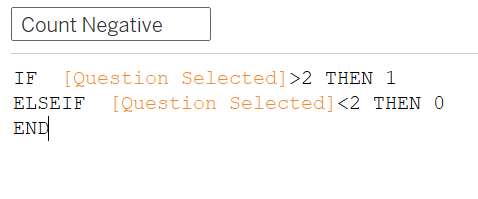
Next, we want to survey responses which are more than 2 (neutral, disagree, strongly disagree) to bear a weight of 1 for a variable called ‘Count Negative’ - this will allow these (non-“pro”) responses to start from left of the middle origin y-axis divider later.
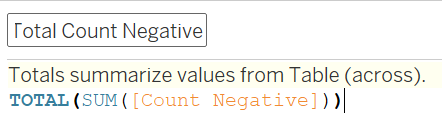
Sum up this variable across the table in the variable ‘Total Count Negative’
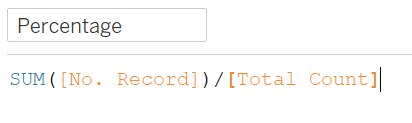
Next, we need the Percentage of responses that selected each response foe the selected question (Strongly Agree, Agree, etc.), out of the total record
And because the divergent bars are ultimately a Gantt chart, we will need a variable to tell the individual response value where to start - by dividing the Total Count Negative by the sum of Total Count (with a negative in front), we will be able to identify where the values bigger than 2 (i.e. neutral, disagree, strongly disagree) will start from the left of the y-axis (note the negative sign at the beginning of the formula below for the variable Gantt Start).
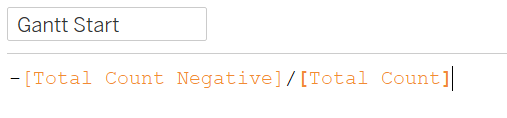
The final variable to create for the basic stacked bars is a little more tricky - we need a variable to tell us how long the bar for each response should be when stacked together. We first find where the bar starts, then add the percentage of the next row, skipping null values (note: up to this step, Tableau will compute this across table, later on we will specify for it to compute using each responded value, together with Gantt Start, Gantt Percent will then start where the previous response value ends, then add all entries with that response value together, then restart for each response value)

Step 2.3 - Divergent Stacked Bar
Now we put everything together. We drag-and-drop Countries to Rows, Gnatt Percent to Columns, change the chart type to Gnatt Bar, drop Question Selected to Colour and another one to Detail, and finally Percentage to Size
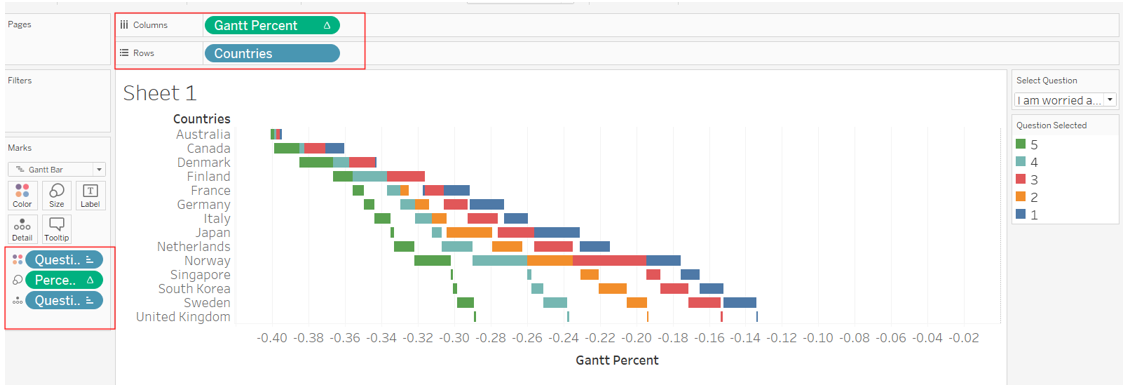
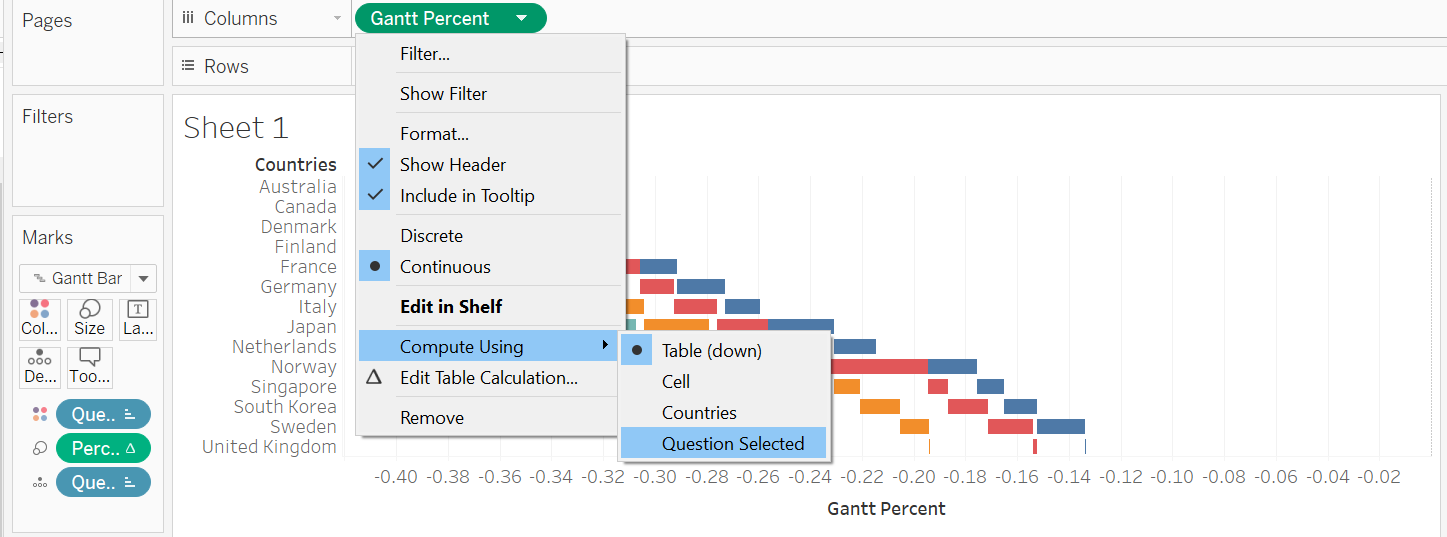
Thereafter, we go to the little triangle on the green Gnatt Percent pill, ‘Compute Using’ option, and select ‘Question Selected’. Do the same for the green Percentage pill under Size.
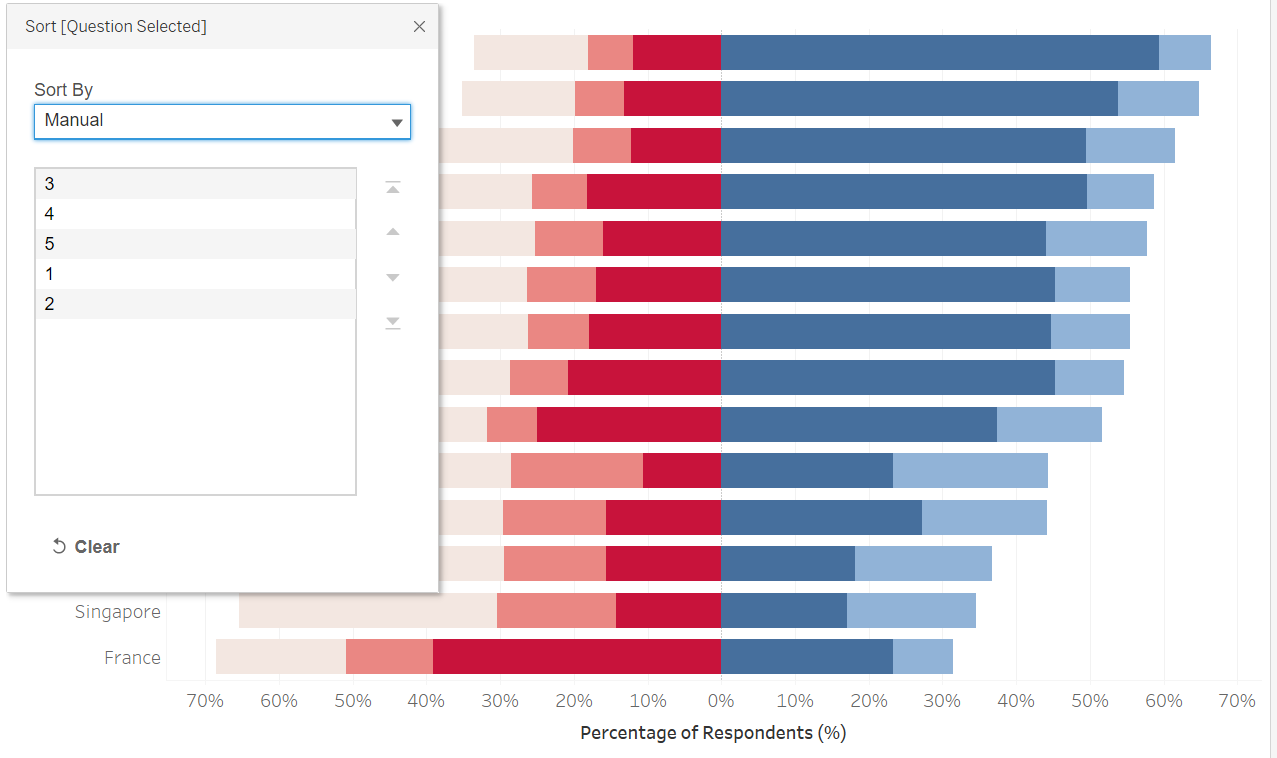
Under Colour, click on ‘Edit Colors…’, select dark blue for 1, light blue for 2, muted neutral color for 3, light pink for 4, and bright red for 5. Right-click on the Question Selected blue pill under colour, and select ‘Sort’. Under ‘Sort By’, choose Manual, and arrange then in 3>4>5>1>2 order (based on conclusion from Section B, we want to put the stronger views in the middle, with neutral at the end of the “non-pro” side)
And there, a basic Divergent Stacked Bar is created! One last touch - to change the negative percentage on the left of Y-axis to positive. Right-click on the X-axis, select Format, under Scale, Numbers, choose ‘Custom’ and type ‘0%;0%’ as the format
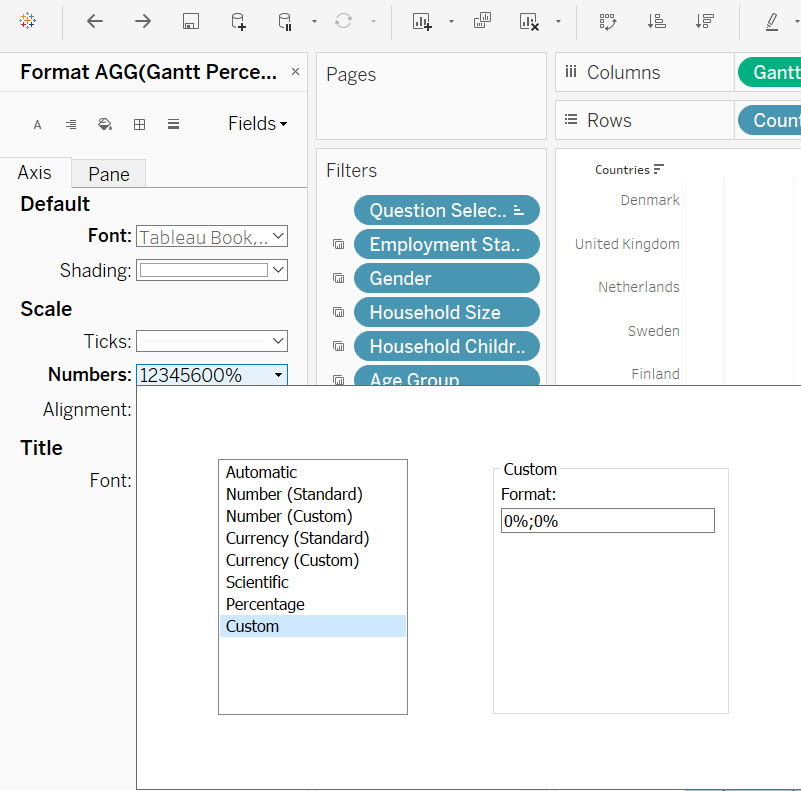
Step 2.4 - Sort Viz
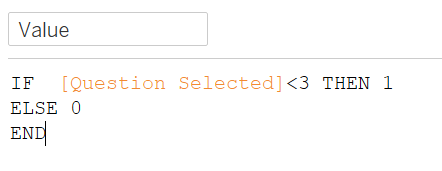
We want to create a sorting variable (which will also be used in the following portion of our viz) to calculate percentage of respondents who provided positive response to the questions asked (i.e. either Strongly Agree or Agree). But first, we need to sum up all the positive responses with a new ‘Value’ field
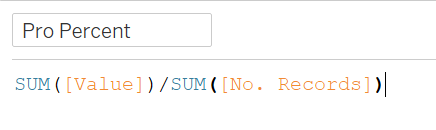
Then divide this value by the number of records to get the percentage of positive responses- “Pro Percent”
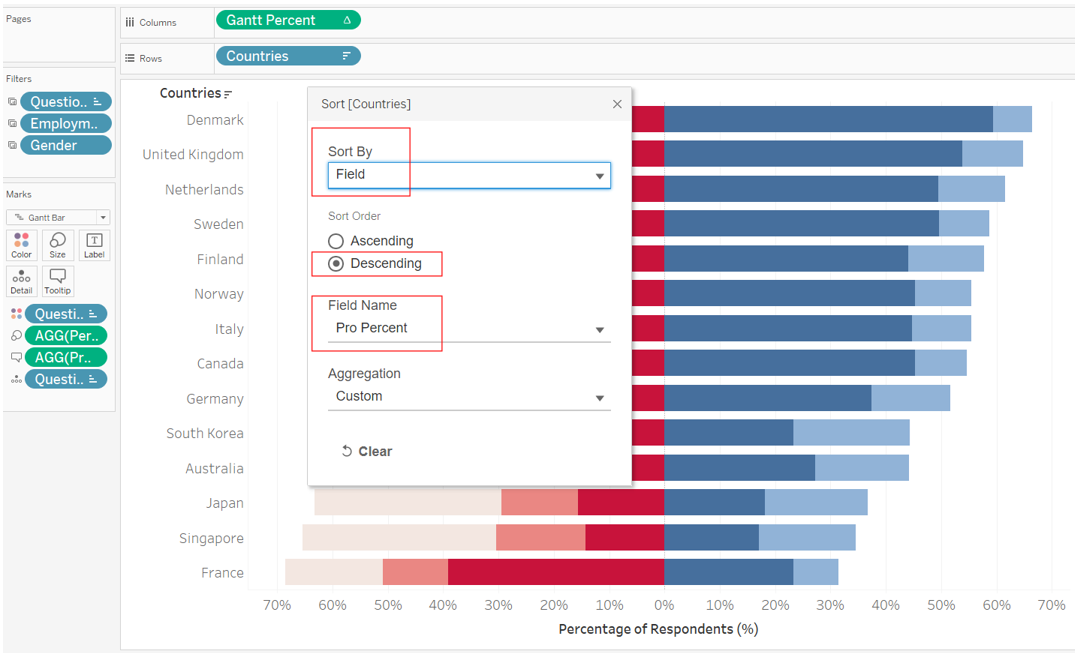
And finally, we can go back to the blue Country pill under Rows, right-click and select ‘Sort’, select ‘Field’ under ‘Sort By’, Descending order, ‘Pro Percent’ under Field Name, and leave Custom as the Aggregation.
Part 3 - Creating Bar Chart to Include as ToolTip
Step 3.1 - Creating Bar Chart
First, create a new Worksheet on Tableau. Before we do anything further, we create a new variable - ‘Ranked Response’ - to transform the 1-5 code into actual description of the response (e.g. Strongly Agree etc.)
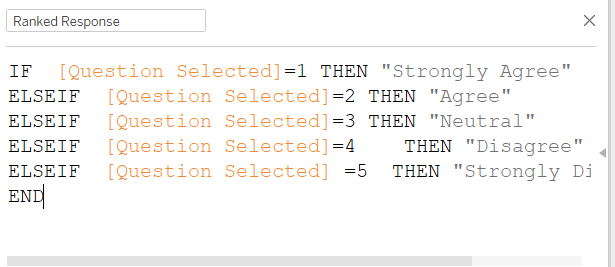
Next, at the new Worksheet, we drag-and-drop No. Record onto Columns, and Ranked Response onto Rows and Color box, then Percentage into Label box. Change the color of the viz using the ‘Pick Screen Color’ option to ensure consistency on the color bar with the main viz. Manually sort the order of the Y-axis to start from Strongly Agree to Strongly Disagree.
Note: When presented as a bar char instead of a diverging stacked bar, it would be more intuitive to transit from strongly positive response to strongly negative ones, since we are not trying to depict a dichotomy/contrast here, but merely to provide additional information of viewers to make visual comparison of the country-wide response. Hence this order instead of aligning with the main viz’s order
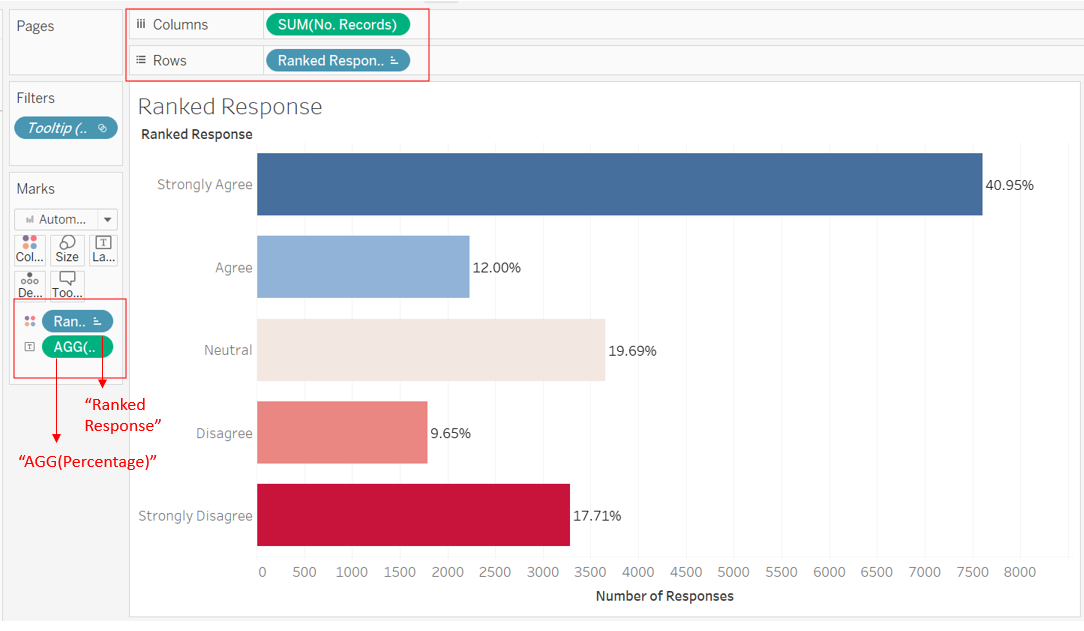
Step 3.2 - ToopTip linking sheets
We head back to the Divergent Stacked Bar sheet. We create one variable Percentage Response that multiplies 100 to the variable Percentage (this will make the ToolTip information more easily interpretable as a percentage of response). Include this new variable, together with Ranked Response into ToolTop box, and input the following into ToolTip
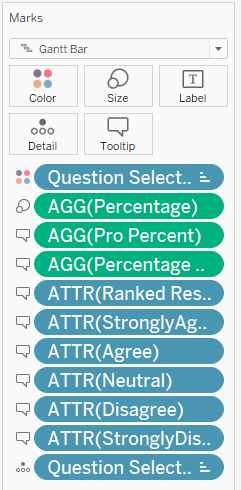
However, we notice that the Ranked Response does not change color when we hover over each of the different ranked responses. Hence, to improve it even further, we create another 5 separate variable to create to color changing effect

The above uses Strongly Agree as an example, the process is repeated to create 4 other variables for the four other response value. Next, put all 5 newly created variable into ToolTip
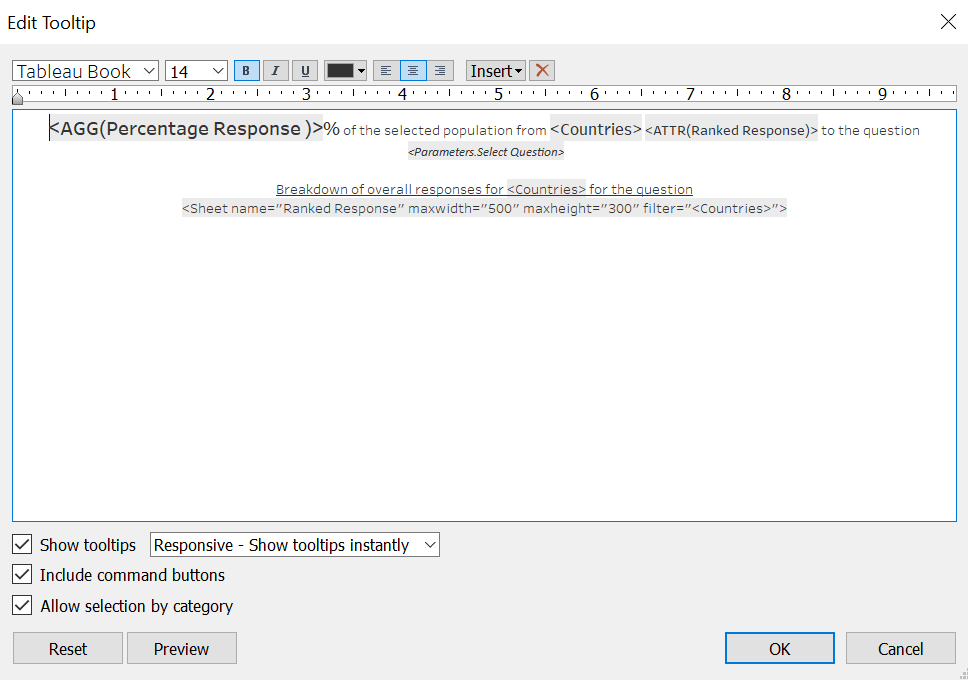
Finally, edit the ToolTip as follows:
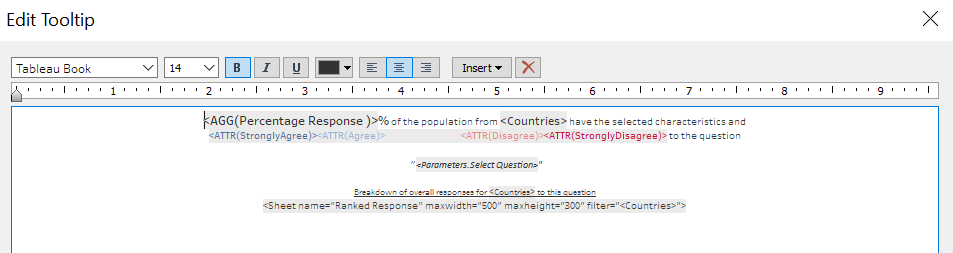
And the complete Stacked Bar Chart with informative summary and ToolTip showing overall survey response from the country is created!
Part 4 - Visualizing Uncertainty
Step 4.1 - Creating Variables Required
We have created two important variables earlier (Value and Pro Percent). Next, we will need a few more variables that measure uncertainty. Starting with the Standard Error

Z-scores 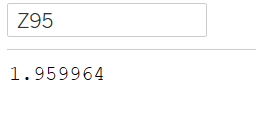
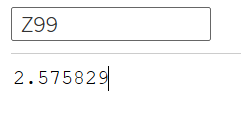
Error Margins 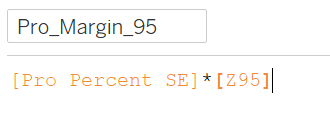

95% Bounds 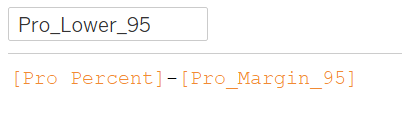
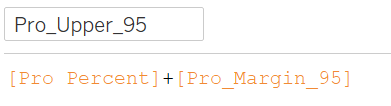
99% Bounds 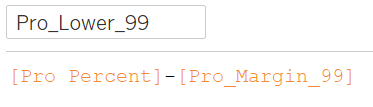
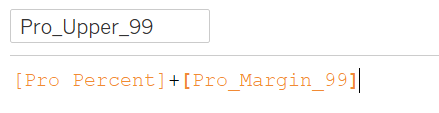
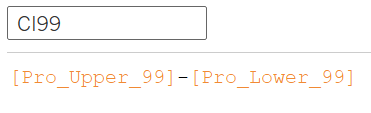
Confidence Intervals 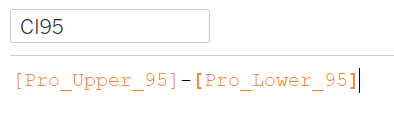
A Parameter to allow toggling between 95% and 99% CI, both, or none to be shown. Select ‘String’ as the Data type, List for Allowable values, and the values and displays as follows 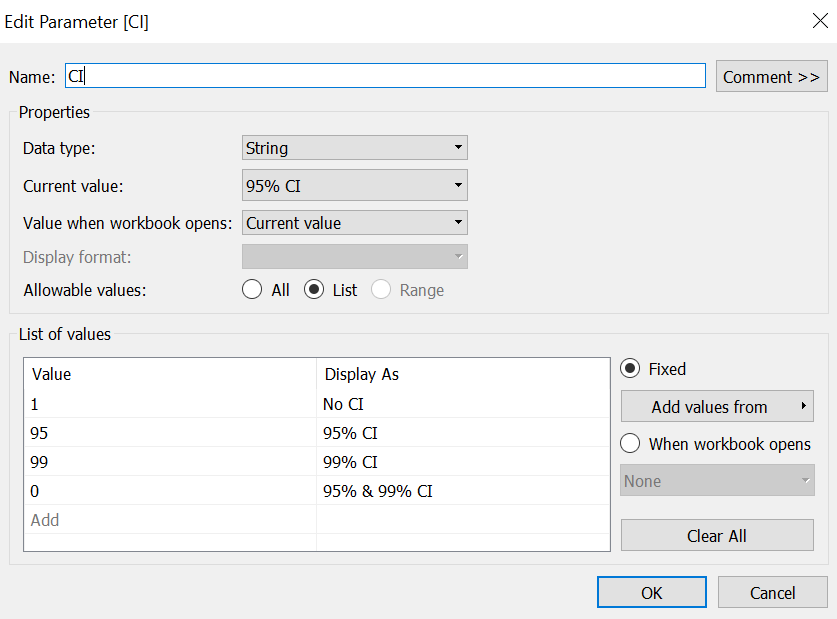
Upper and Lower Bounds for the two different confidence level 
And one final variable to display the absolute percentage point of uncertainty from the estimated proportion - the Confidence Interval, which will show 99% CI for all cases except when only 95% CI is chosen for the parameter. 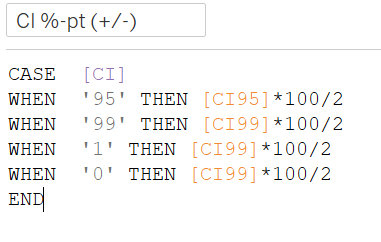
Step 4.2 - Creating Basic Uncertainty Viz
First, drag-and-drop Countries onto Rows and Pro Percent onto Column
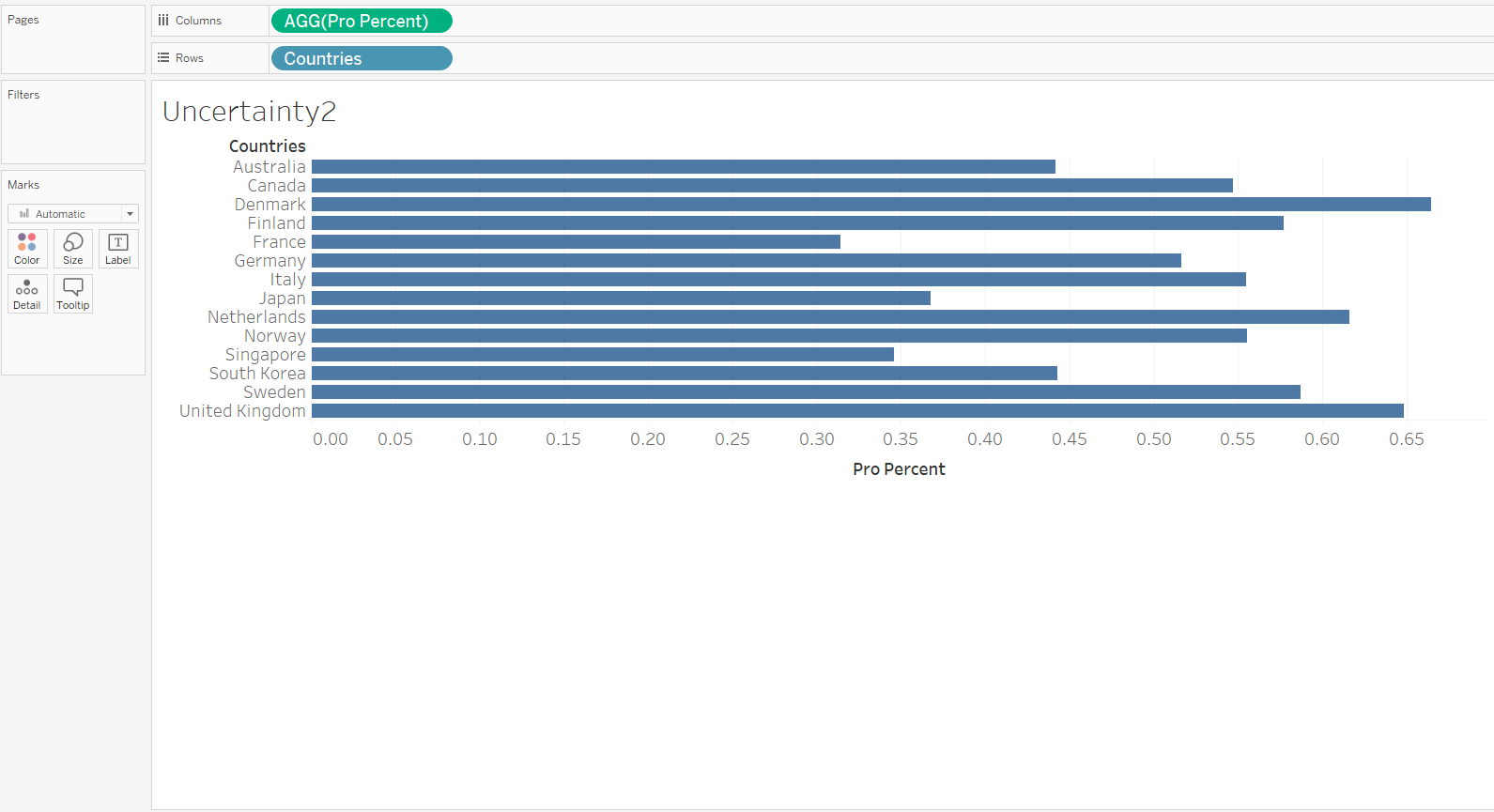
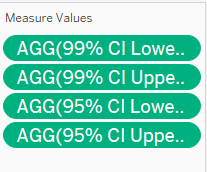
Next, drag-and-drop Measure Values onto Columns; a list of variables will appear on the Measure Value panel to the left of the viz, remove all except the four upper/lower bounds for 95%/99% CI (as shown below). On the Measure Value green pill under Columns, right-click and select Dual Axis,
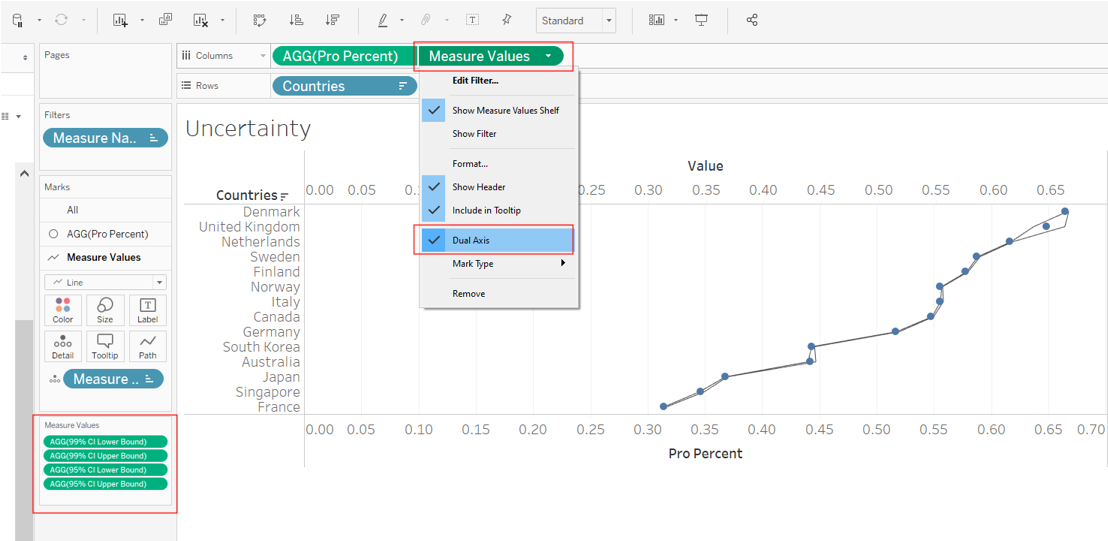
On the Measure Values tab under the Marks panel, select Line as the chart type, then drag-and-drop the blue Measure Names pill from Detail to Path. Click on Color to change it to a grey color to distinguish from the dotted mean, and reduce the size of the lines.
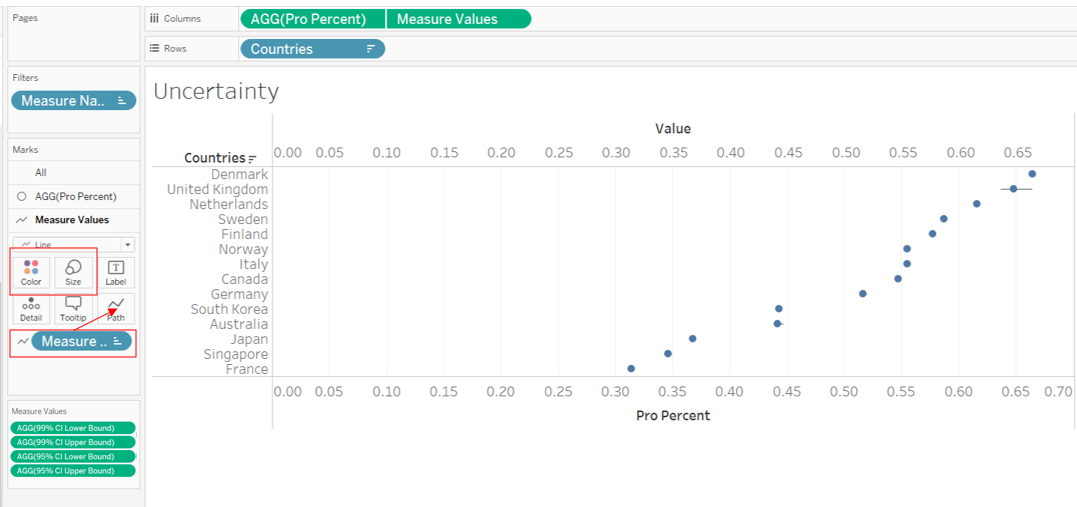
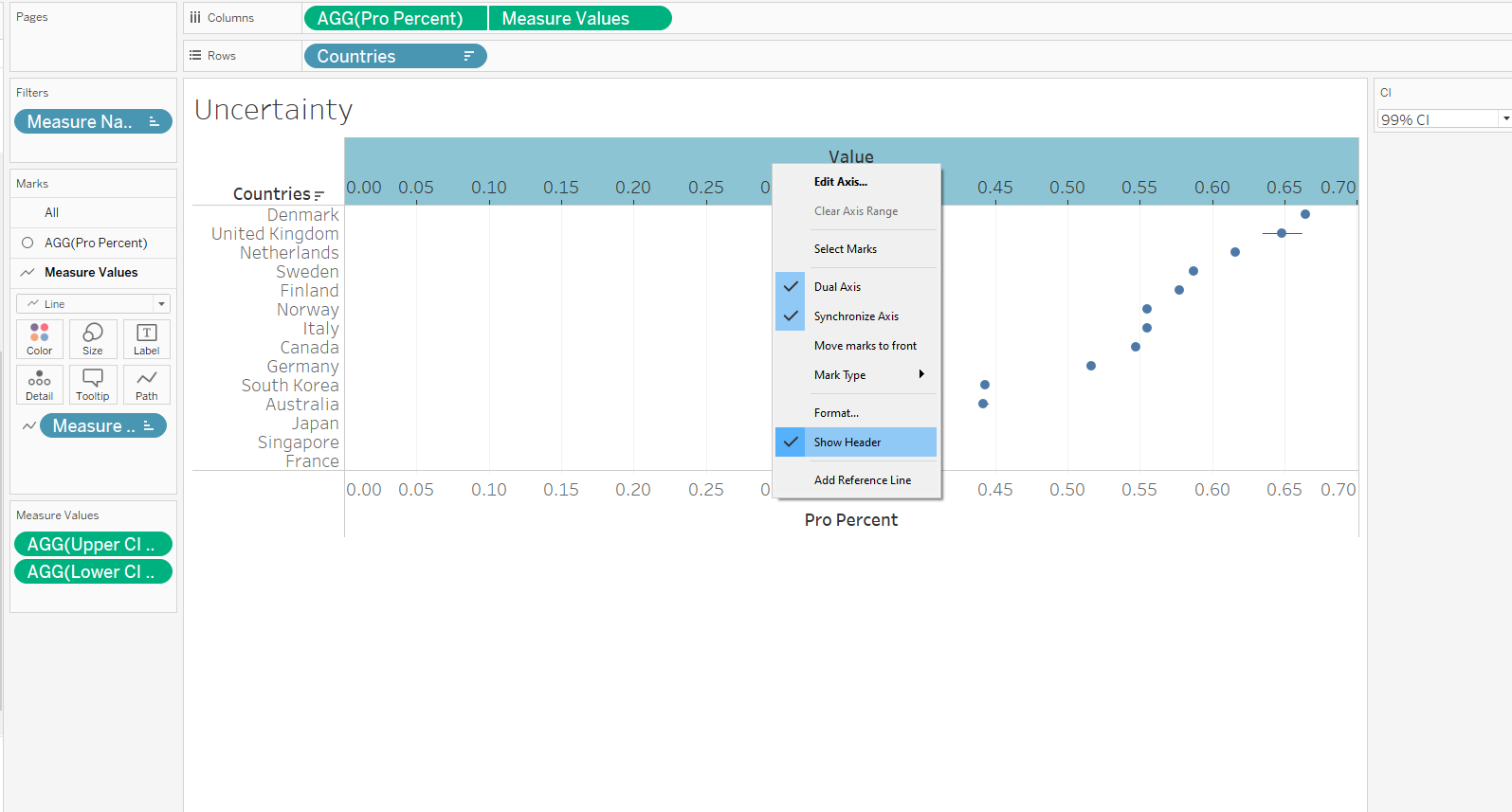
Right-click on the top Axis to select Synchronize Axis, then uncheck Show Header to turn it off.
Sort the Y-axis by descending Pro Percent (as with earlier Divergent Stacked Bar viz to synchronize)
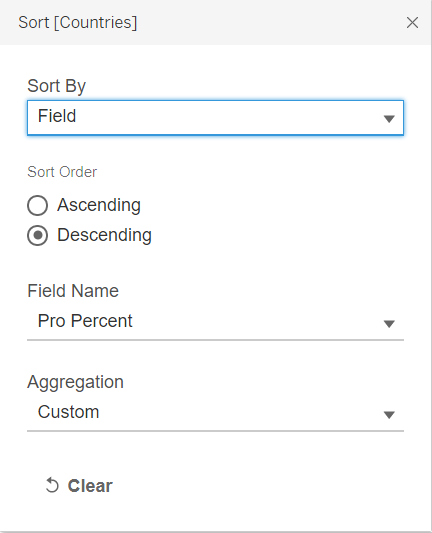
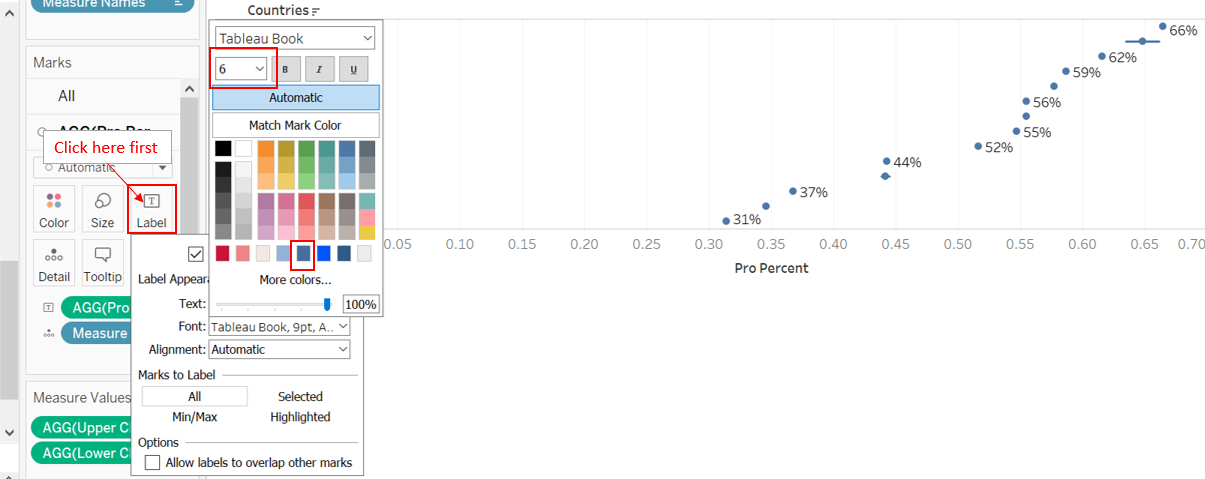
On the AGG(Pro Percent) tab under the Marks panel, drag-and-drop Pro Percent to Label; edit the labels to a smaller font (6pt) and ensure the format is Percentage (no decimal point). Formating can be done by right-clicking on the green Pro Percent pill under Label and selecting “format”. Similarly, X-axis should also be in Percentage format, and formating can be done by right-clicking and selecting ‘format’ as well (Under the Axis pane, go to ‘Scale’ segment, under ‘Numbers’, select ‘Percentage’). Right click on the X-axis and select ‘Move marks to front’ if not already at the front.
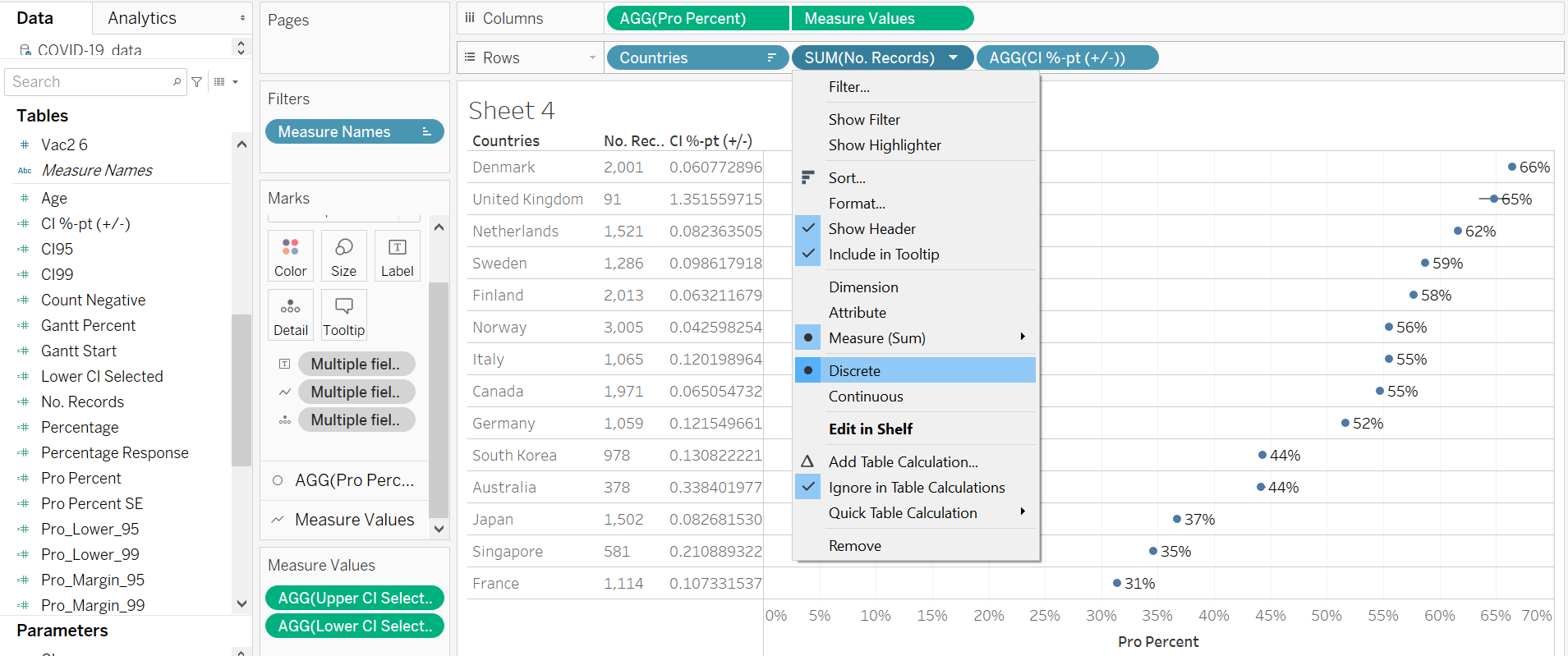
Select Entire View on the view option. Drag-and-drop both the ‘CI %-pt (+/-)’ and ‘No. Record’ variable onto Rows, then click on both the pills to change them from Continuous to Discrete (see below). Format the ‘CI %-pt (+/-)’ rows to retain 4 decimal points.
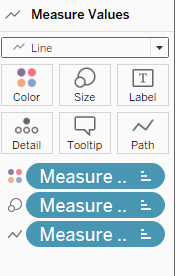
Next, we allow the error bars to change according to the CI we have selected. First, drag-and-drop Measure Names into both Color and Size.
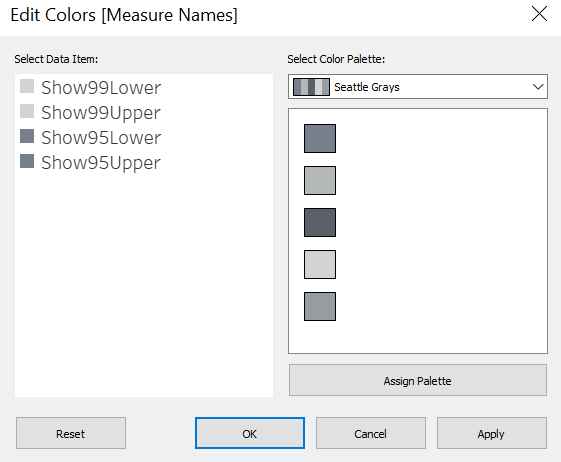
We then adjust the color of the bar to let 95% CIs (which are shorter) be of a darker grey, and 99% CIs be of a lighter grey - Double click on the color palette on the right under the header “Measure Names” then select the desired color (using the Seattle Grays palette makes life easier - just choose two from the 50 shades of gray…)
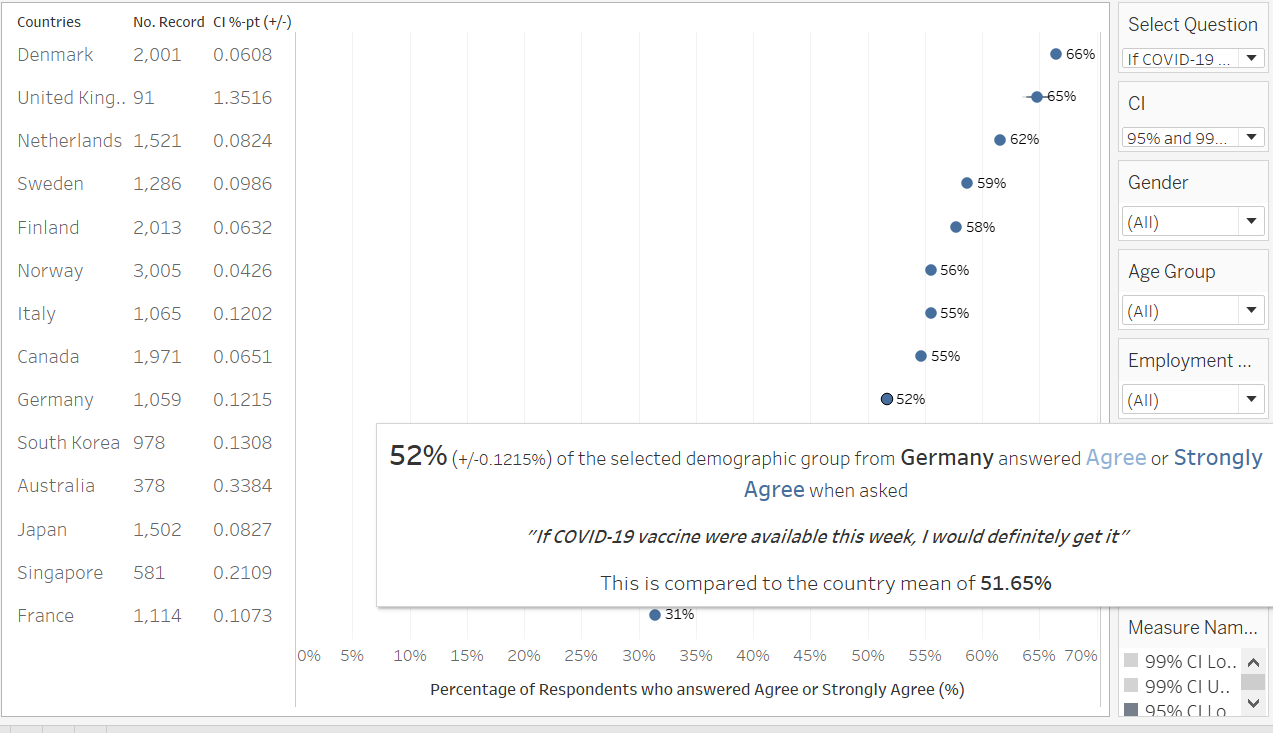
Next, edit the sizes of the data information (by right-clicking the relevant areas and selecting ‘format’ to change the sizes, generally to size 7), reduce data ink (row dividers were removed to reduce data ink, this can be achieved by right clicking the via area, selecting ‘format’, under the Border tab, under Rows, select None for Pane), and change the axis title (see below) to “Percentage of respondents who answered Agree or Strongly Agree (%)”. And there we have our basic uncertainty viz
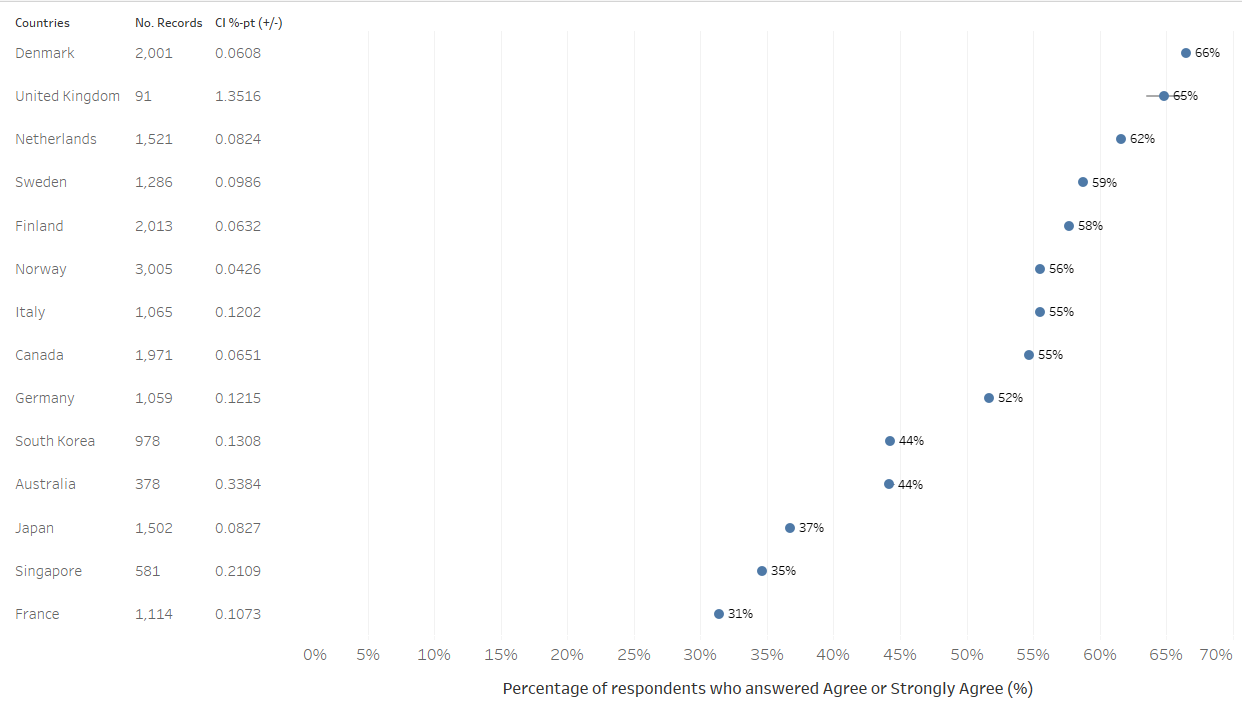
Step 4.3 - ToolTip
We include a ToolTip to summarize the data points when hovered over. Before that, we create an extra variable showing the country’s mean percentage who responded positively to the selected question - “Country Pro Percent” - this will come in useful when we add on filters to allow toggling into sub-populations (see next step). With this Country Pro Percent, we would then be able to compare the sub-population’s positive response rate vis-a-vis the country’s average.

Finally, we add on the ToolTip by clicking on the ToolTip box, where an editing box will pop up, and input as shown below
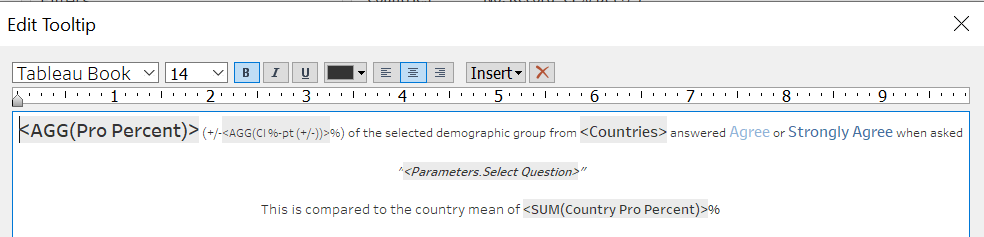
Step 4.4 - Filters
Before we put everything together, let’s create one more filter - Age Group - by creating a new calculated field as follows.

We then drag-and-drop Gender, Age Group, Employment Status, Household Size, and Household Children onto the Filter panel, show all the filters. To optimize space, we will change Gender to single value drop-down, while the rest of the filters to multiple-values drop-down. Find the two Parameters on the Parameters panel on the bottom-left, and show both the Select Question and CI parameters as well.
For each of the filter, we click on the small triangle beside them, go to ‘Apply to Worksheet’, select ‘Selected Worksheet’ and check the box beside ‘Divergent Stacked Bar’ sheet. 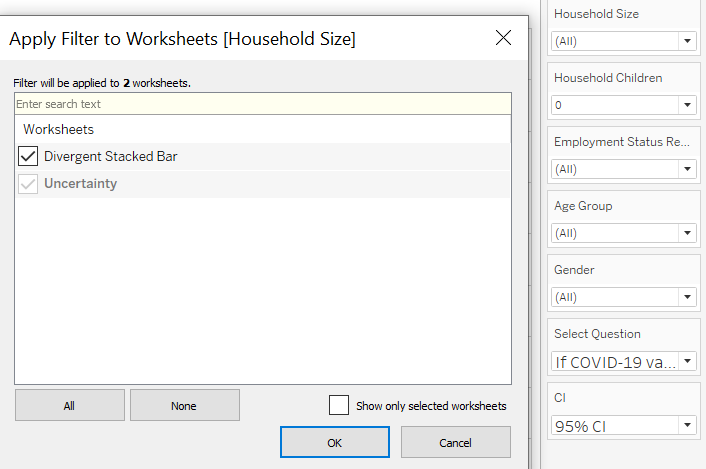
And there we have it, the final Visualization for Uncertainty with informative ToolTip. While the lines for the standard error margins are small in this version, it will be more obvious when we explore sub-population of each country by filtering down the dataset, which will lead to smaller number of records being available.
Part 5 - Interactive Dashboard
Step 5.1 - Basic Dashboard
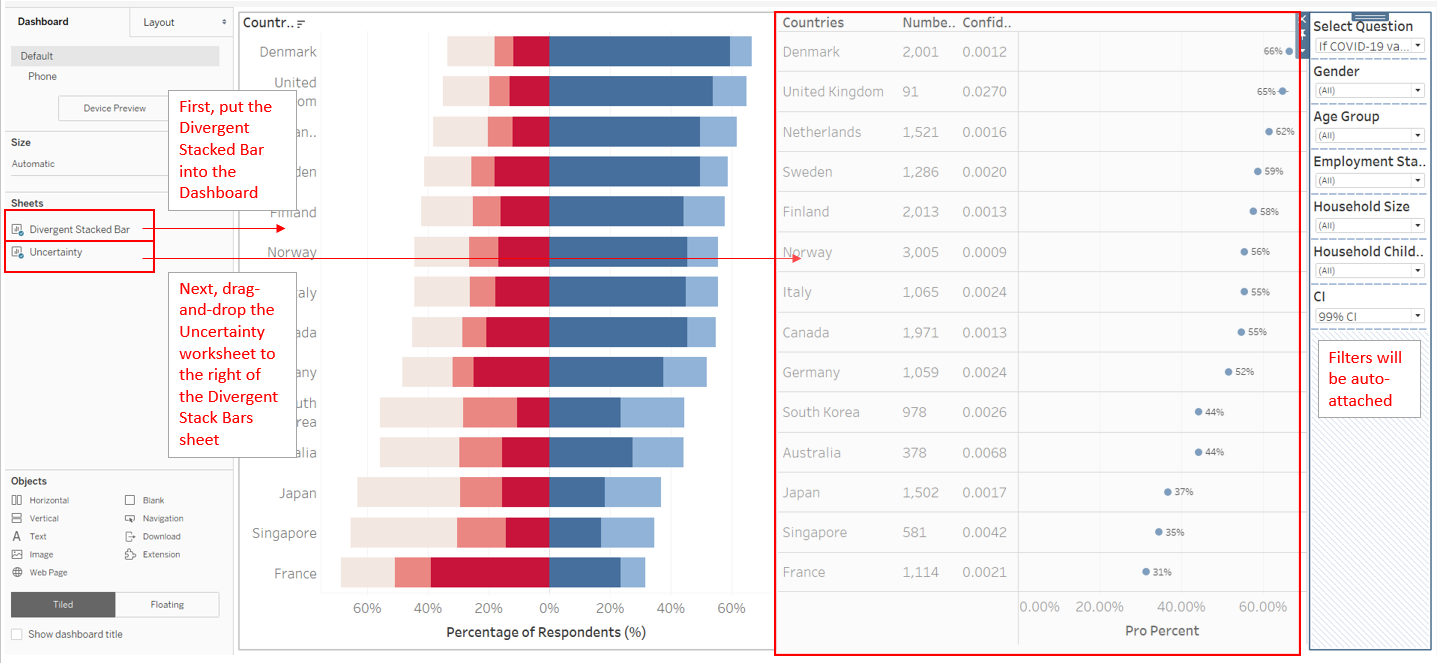
Putting them altogether is easy: first, drag-and-drop both the Worksheets onto an empty Dashboard: Diverging Stacked Bars worksheet first, then the Uncertainty sheet to the right, the parameters/filters will be automatically attached.
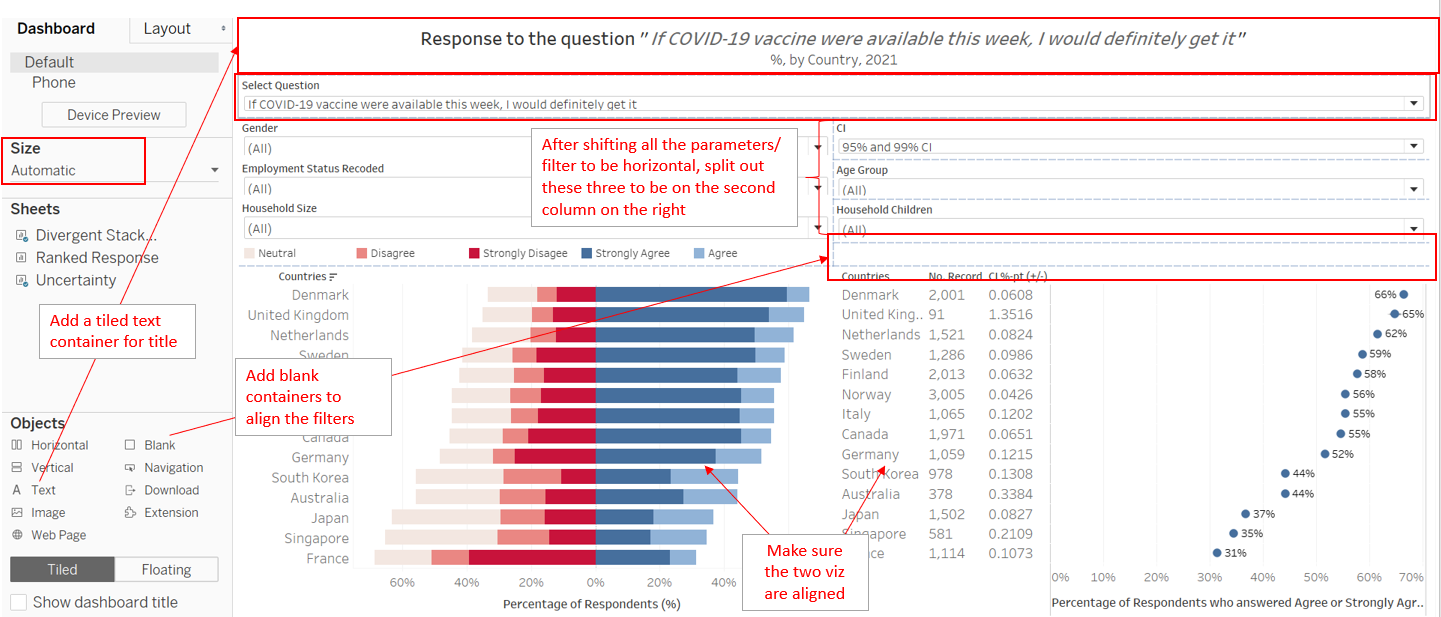
Next, reconfigure the parameters and filters to go to the top of the page by shifting them around. Next, add in a Text Tiled object on top of the parameters and filters to input the title and subtitle. Lastly, change the Size to ‘Automatic’
Step 5.2 - Final Dashboard with Action
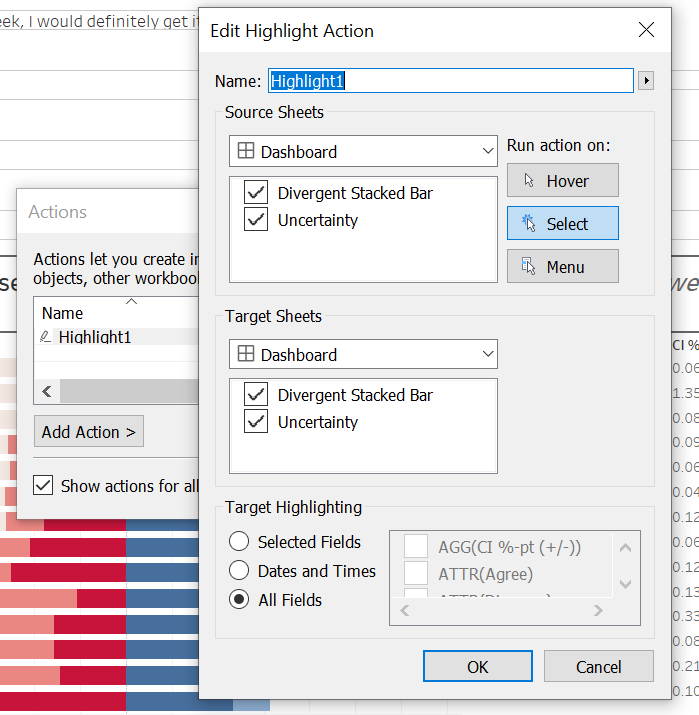
Final step for this visualization is to add Actions: go to the Dashboard tab on the top, click on ‘Actions…’. Click on Add Action, then Highlight, and connect both sheets on the Dashboard with both sheets, running action on select.
And there we have it - the final dashboard!
Step 5.3 - Upload
And once all is done, we upload the viz onto Tableau Public
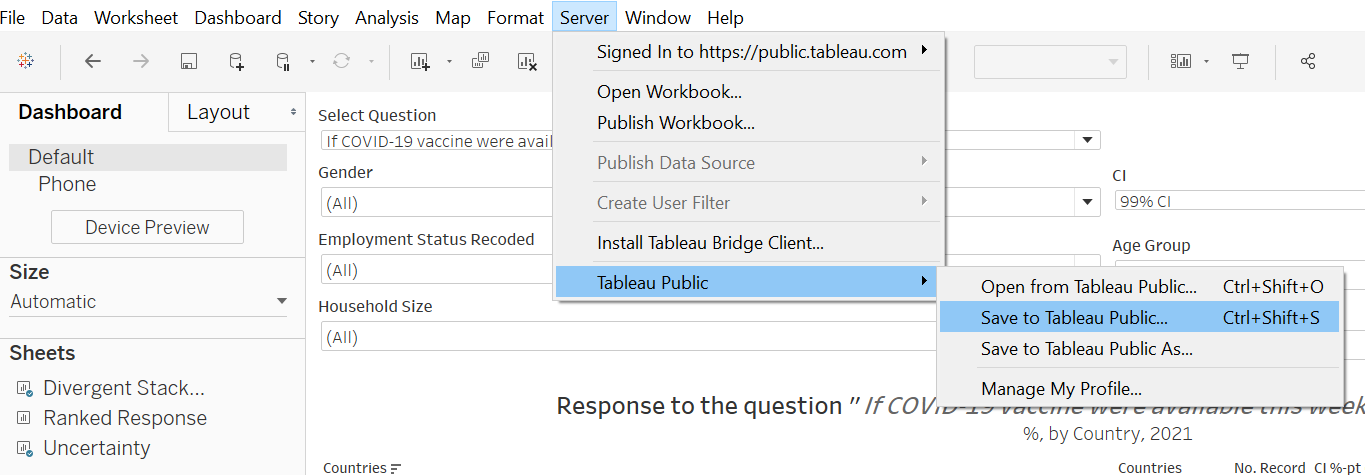
This Visualization is made available on Tableau Public via this link
Section E: Observations
Observation 1 - Austra-Asian countries are less eagar for vaccination
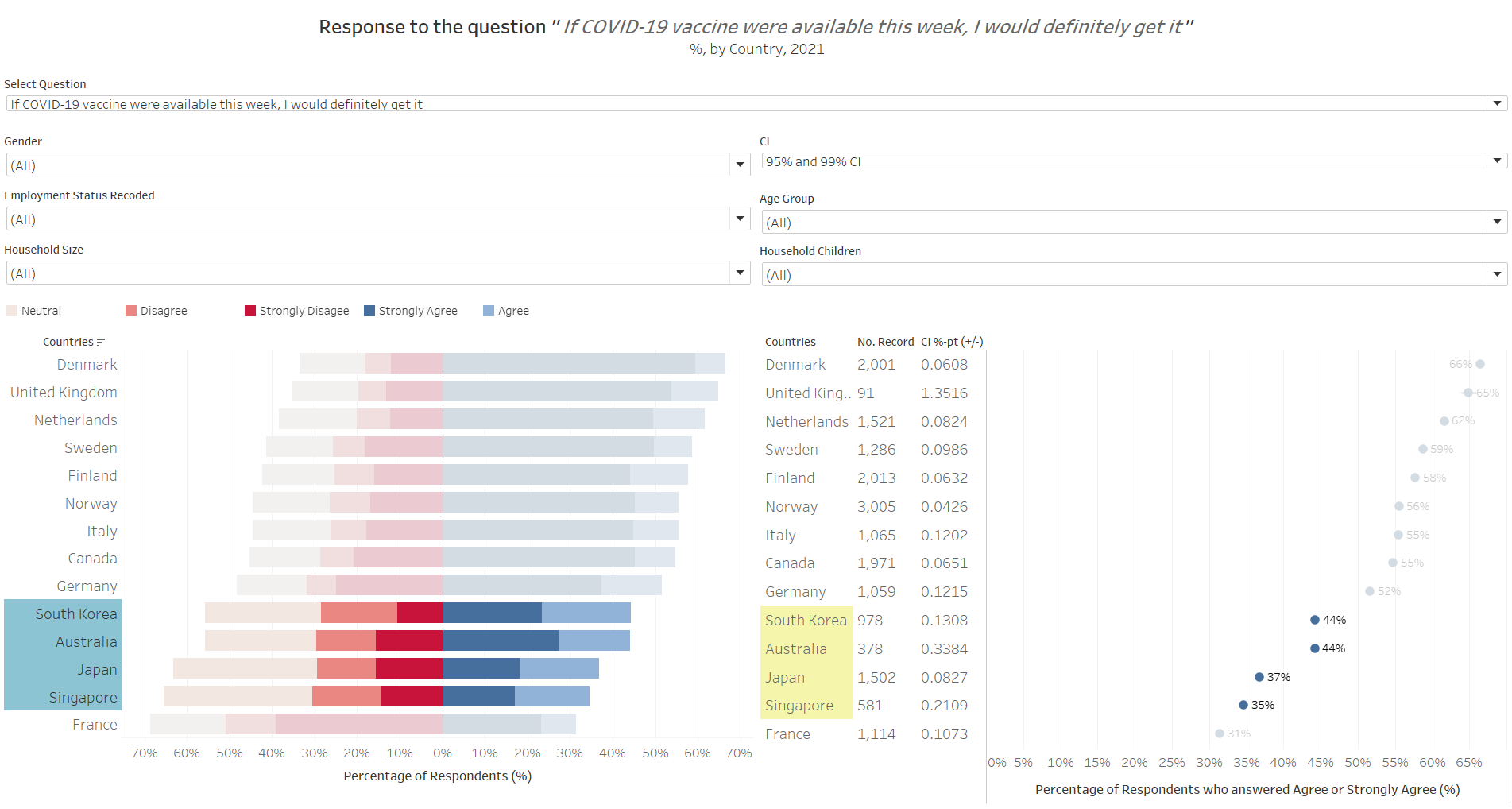
When asked to respond to the question: “if Covid-19 vaccuibe were available this week, I would definitely get it”, Australia and the three Asian countries (South Korea, Japan, Singapore) generally answered less favorably as compared to the other countries. In fact, more respondents were non-pro than pro-vaccination (pro-vaccination being defined as those who answered “Strongly Agree” or “Agree” to the subject survey question) - with the pro-vaccination proportion of the sample being only between 35-44%.
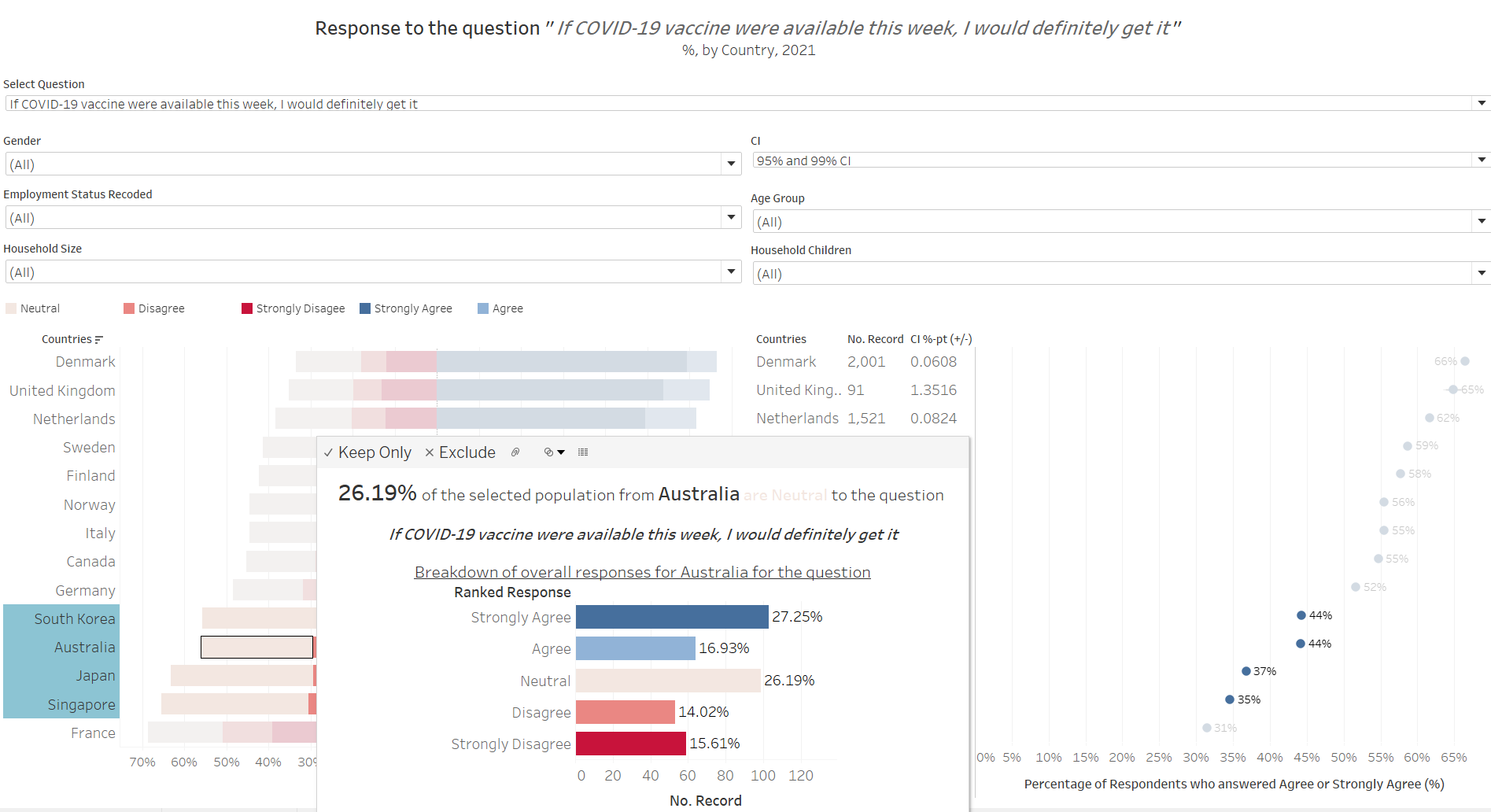
Of course, on closer examination, this is mainly attributable to these countries having some of the most undecided group of people among those presented - around one in four respondents selected “3” (representing “Neutral”) on the ranked scale for this question. Even discounting the neutral group, these four countries also have the least “strong” opinions - that is, they have the least “Strongly Agree” and “Strongly Disagree” responses.
Responses are slightly more “positive” when we consider a one-year time-frame, i.e. when answering the question, “If a Covid-19 vaccine becomes available to me a year from now, I definitely intend to get it”, with the “pro” proportion to this question for the four countries around 48-57%. While one could proposition could be that these countries are less afraid of the virus…
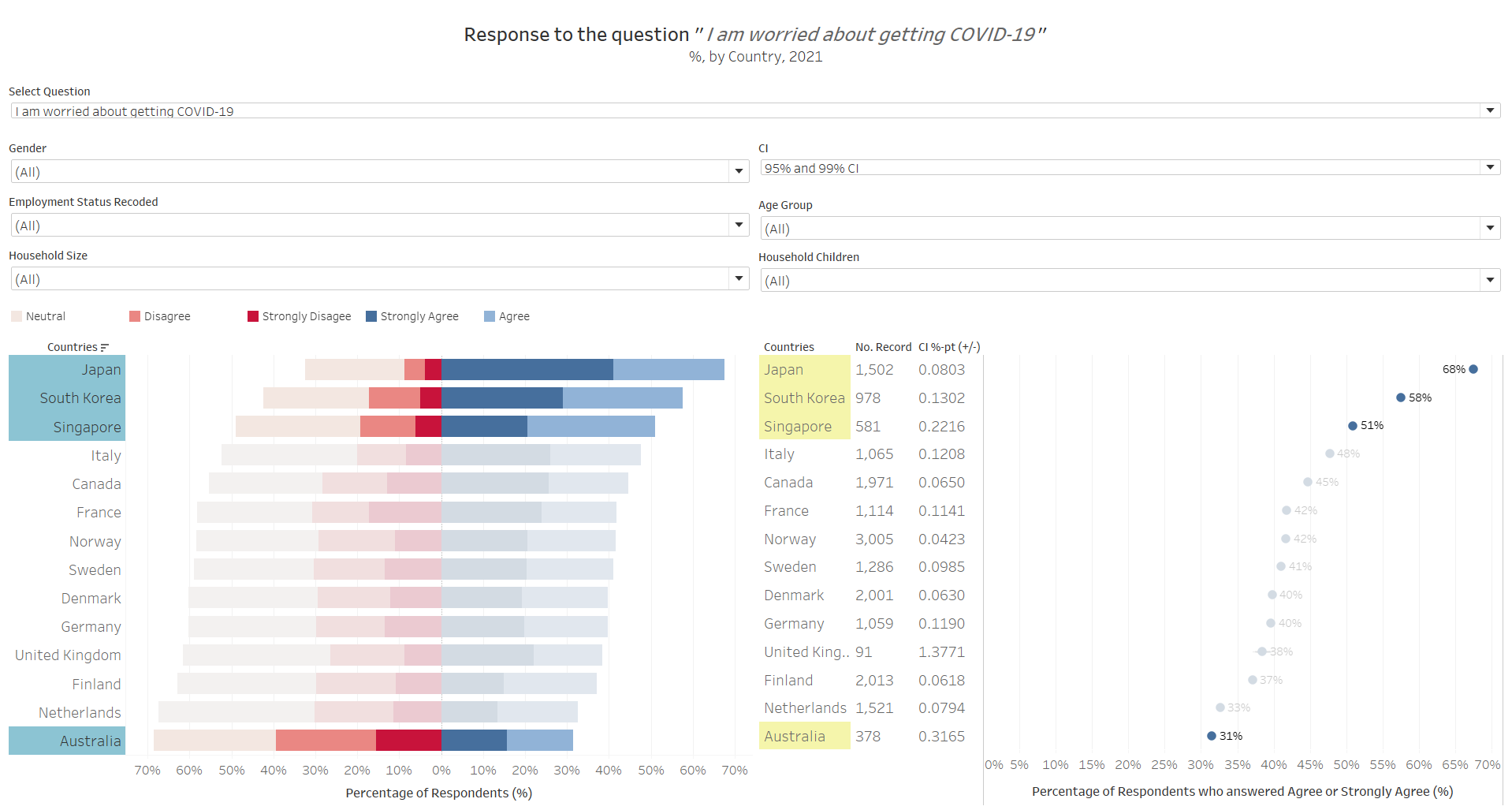
The data seems to show otherwise. Only Australia seems to be rational to this fact - that they are not as worried about the virus as compared to the other country population and hence have less urgency in wanting the vaccine. The Asian countries, though, seems to contradict this postulation: why, then, do the three Asian countries sit on the fence while being worried about the virus? The answer lies in the following:
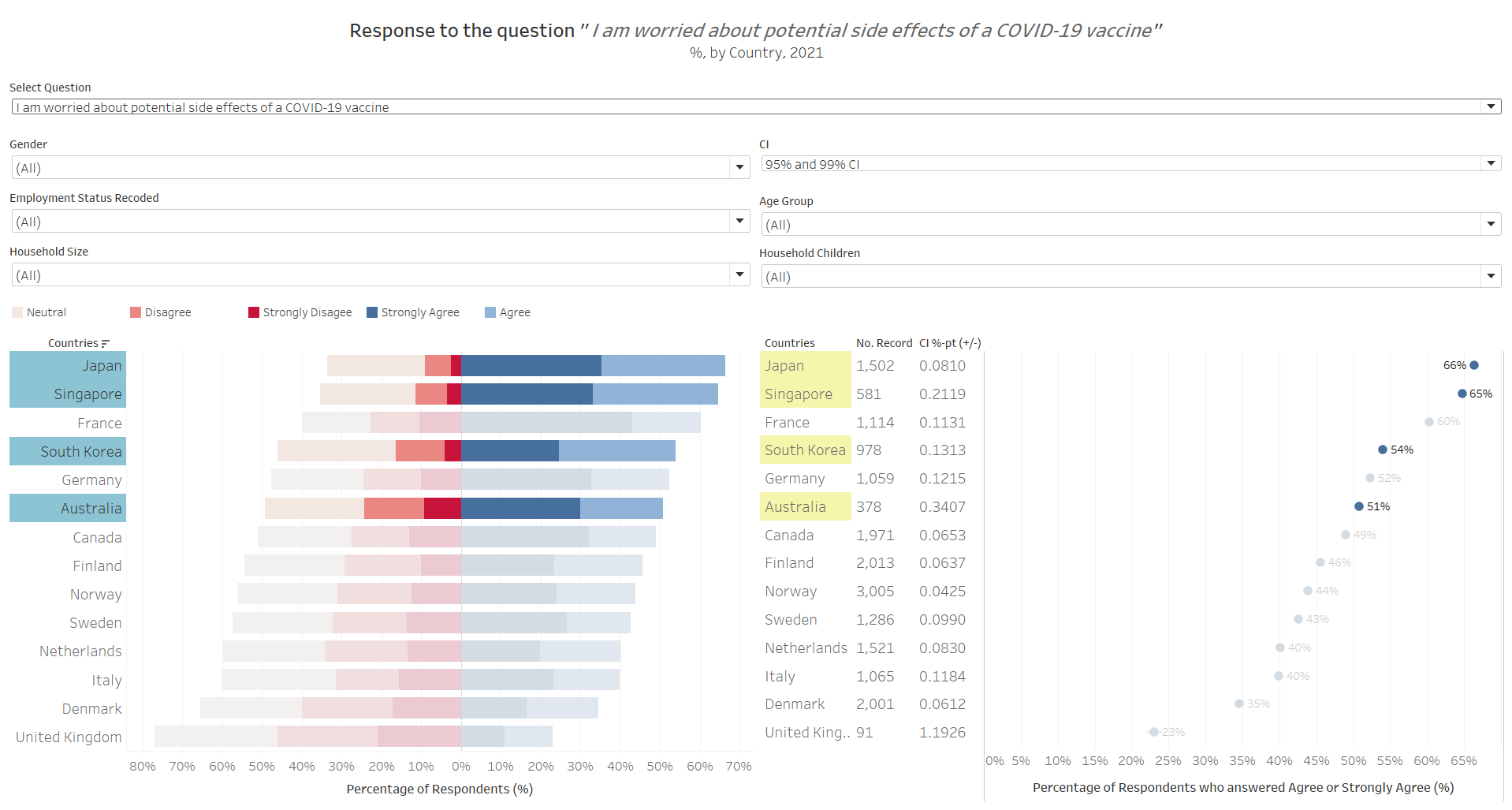
While worried about the virus, the Asian respondents are also skeptical about the vaccine and its side effects. This might partially help explain why some of those who are hesitant to take the vaccine immediately, are more receptive to it one year later - perhaps the reasoning is to allow more clinical findings on the side effects, before they are sure of the vaccine. And before we conclude that this could be due to cultural influence, we should also note that France, as an anomaly vis-a-vis other Western countries, also exhibit similar, if not more extreme (less on the fence, more strong views on “anti” vaccine than pro), responses.
Note: another proposition could be that death rates are lower in the Asian countries and France as compared to the other countries, and hence the respondents from these countries are not as worried. However, a cross-reference to the death rates by country disproofs this theory - while Singapore indeed has one of the lowest death rates due to Covid-19, Franch has a high total number of death (7th gloablly) and death rate (22nd globally), while Japan’s total death also ranked at 37th globally.
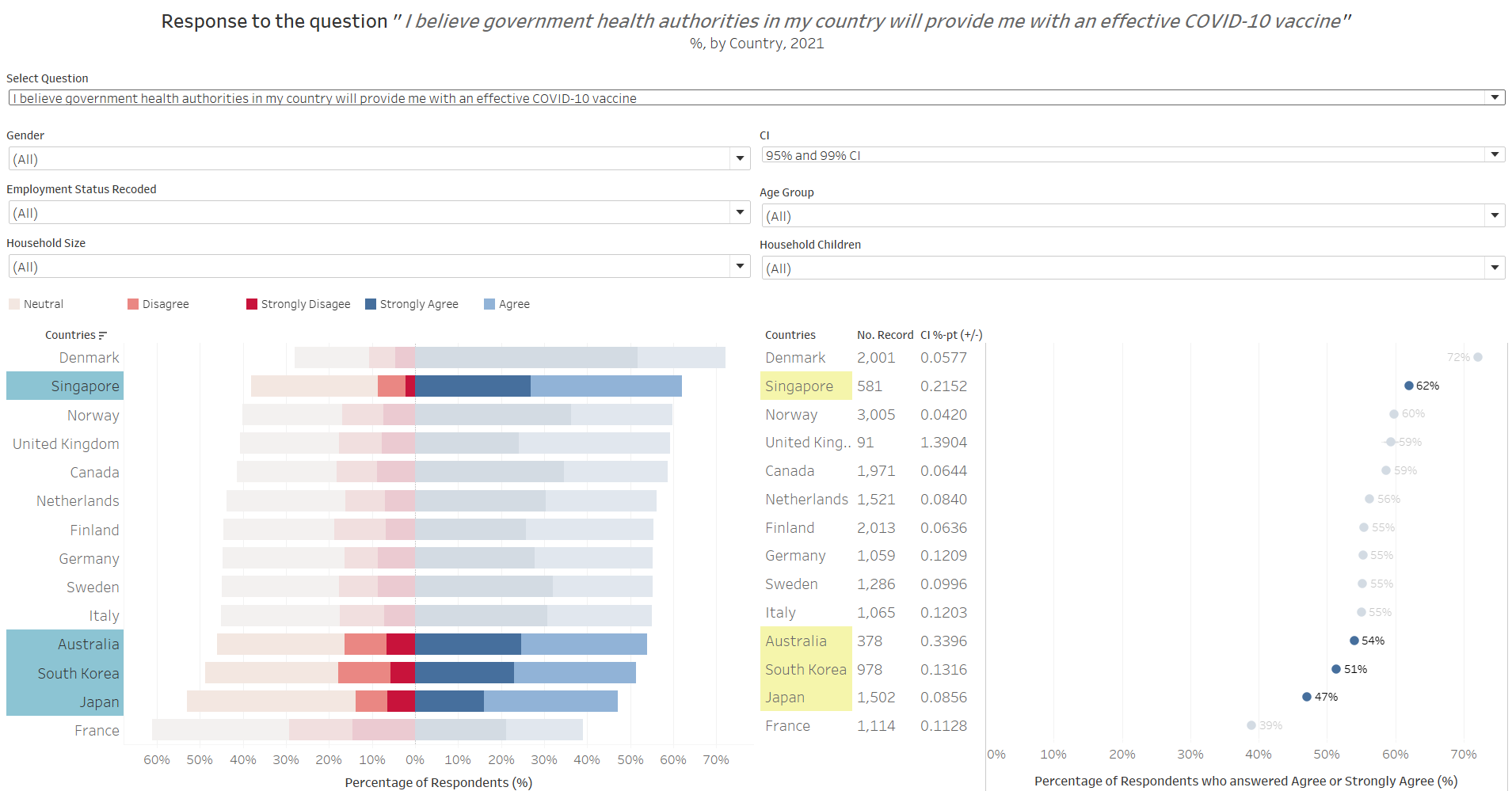
As an added nugget of wisdom - it appears that Singaporeans, while skeptical of the vaccine, have good faith in its government (the other countries skeptical about the vaccine, not so much):
Observation 2 - Smaller households without children appears to be more eagar for vaccination
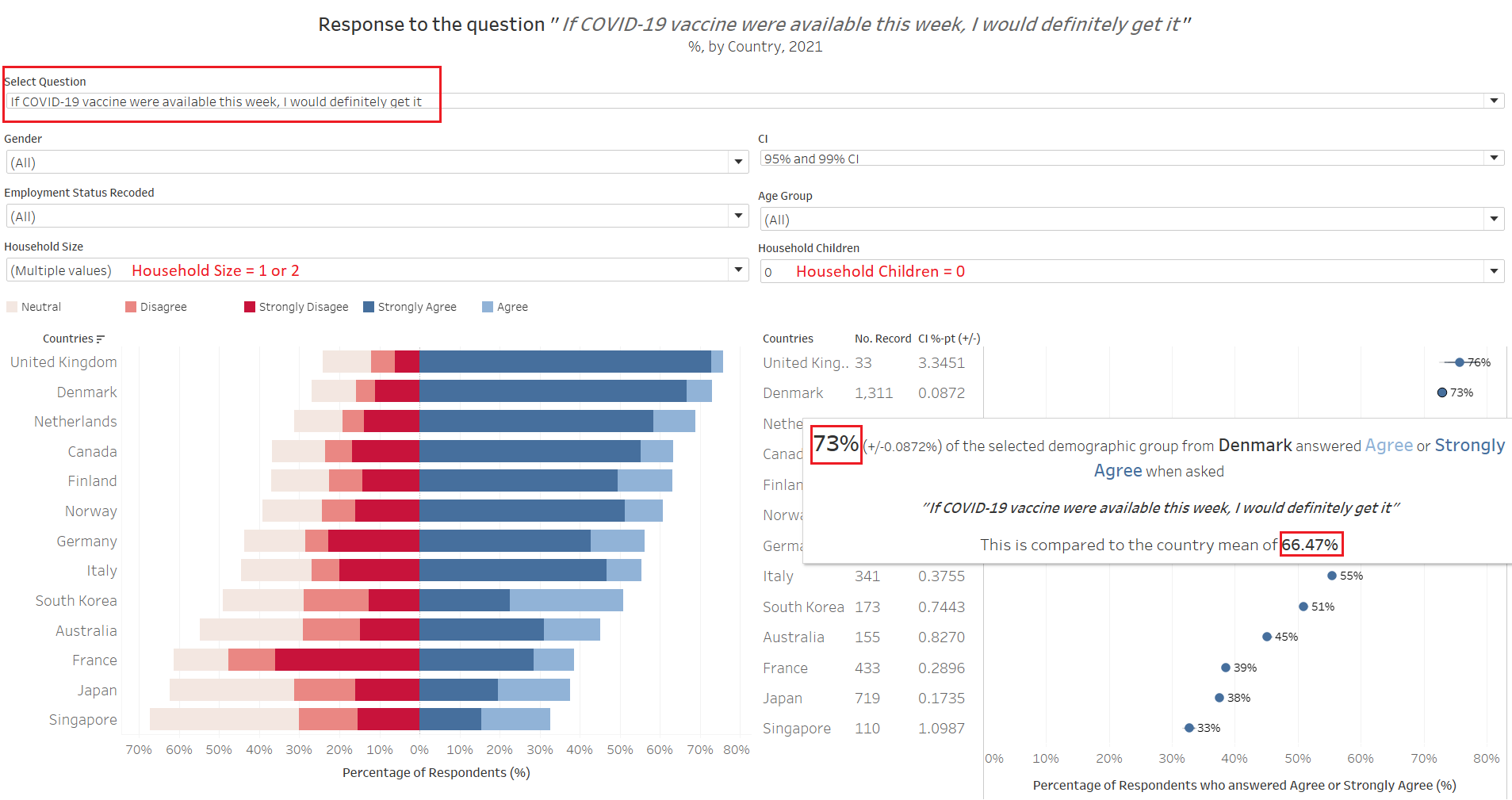
When the dataset is further filtered down to include only respondents with no children in household and has a household size of 1 or 2, it can be observed that this sub-sample population are more “pro” vaccine than the national averages. In the above example using Denmark, we see that 73% of these small-households-without-children respondents responded positively to the qustion on whether they would get the vaccine if it was available this week, which is about 7 percentage points higher than the country mean of around 66%. This observation, in fact, is observed across all country in the dataset. This is similarly observed across all countries (i.e. small-household-without-children are more pro than national average) when we change the question to ask about respondent’s opinion if vaccines were available one year from now.
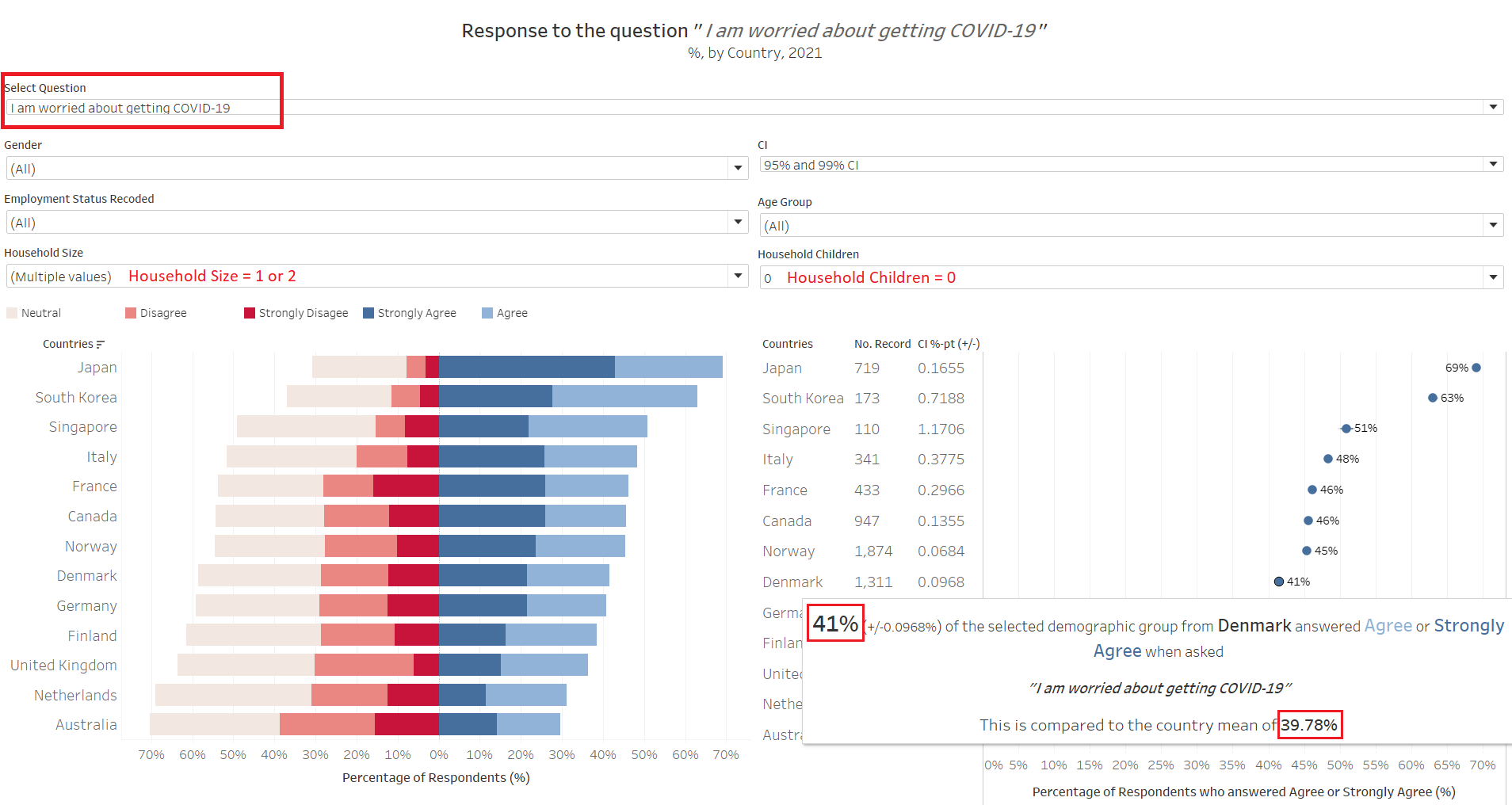
Somewhat intuitively, this small-household-without-children group are also more worried about the virus. But who exactly are these small household respondents who are so worried and eagar for vaccine though - are they young single or recently-married adults without kids, or the old elderly couples staying away from their children?
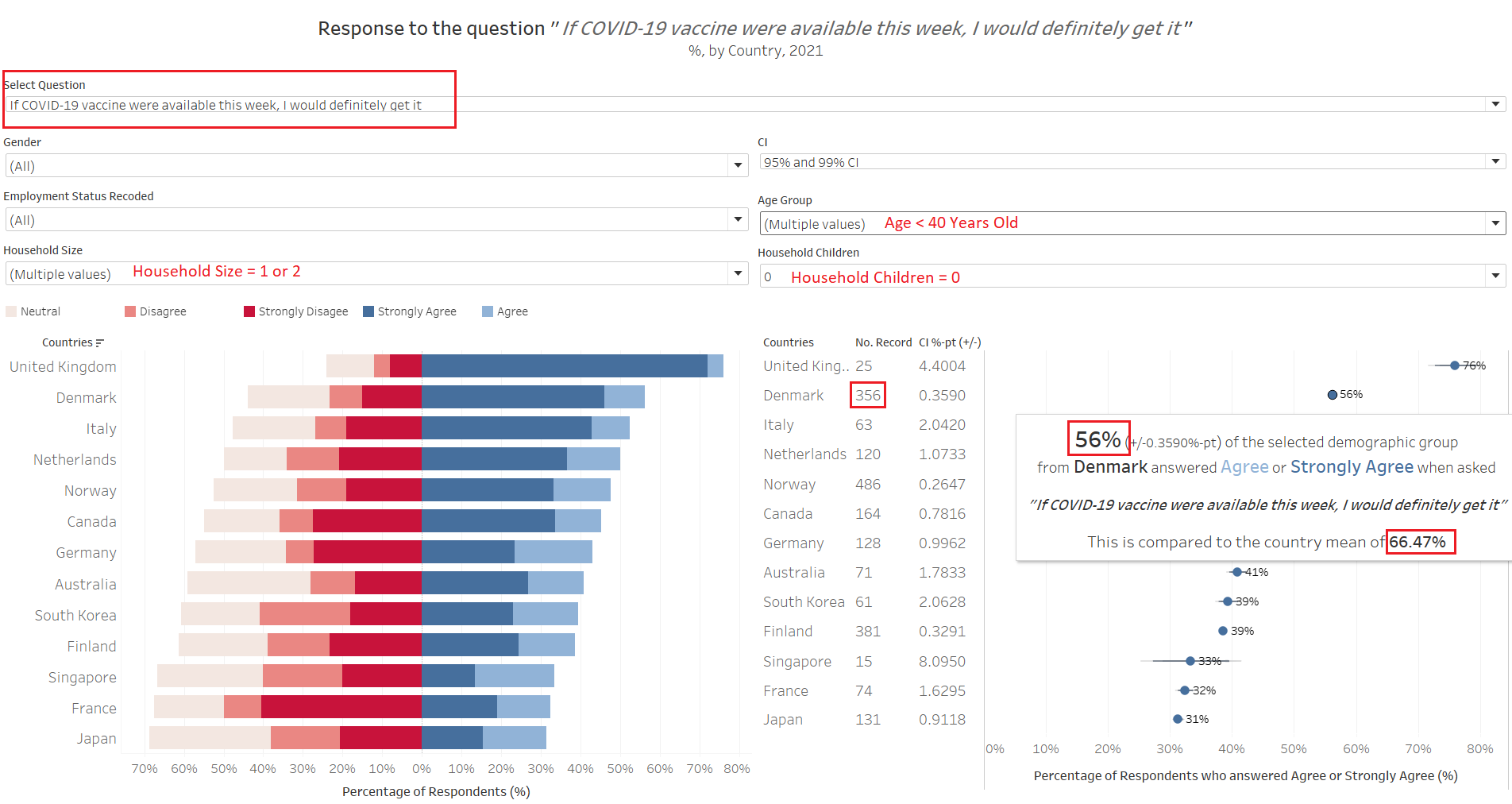
First, we examine those less than 40 years old within this sub-population of small-household-without-children. We notice that their “pro” proportions are not as high as the country mean - take Denmark for example, this group has 56%, as compared to the national average of 66%. This is generally observed for all the other countries, except United Kingdom - which we should take with a pinch of salt as the number of sample records available for this sub-population is only 25 (similarly, Singapore’s data as well, since there are only 15 data points in this instance).
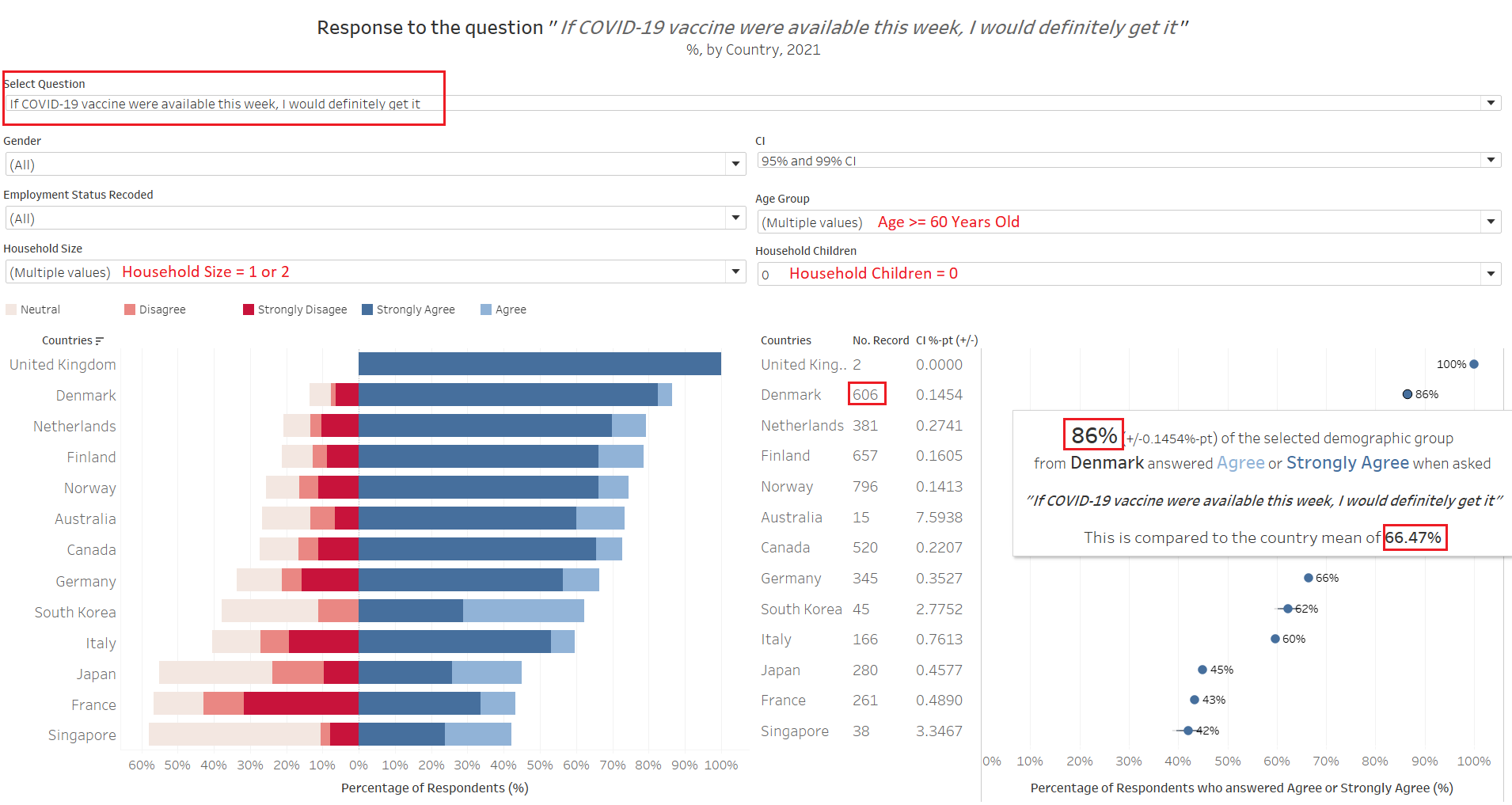
Indeed, across all countries examined those 60 years and older within the small-household-without-children are much more pro-vaccination than the national average. Taking Denmark’s as example, those who fall under this sub-category are almost 20%-pt higher in their “Agree” and “Strongly Agree” responses as compared to the country’s mean. This big difference is observed across all countries. What is notable as well is that the number of respondents 60 years and older is much more than the number for respondents younger than 40 years old (except for UK, Australia, and S. Korea). This would mean that the older population’s opinion would have a larger weight in the country mean.
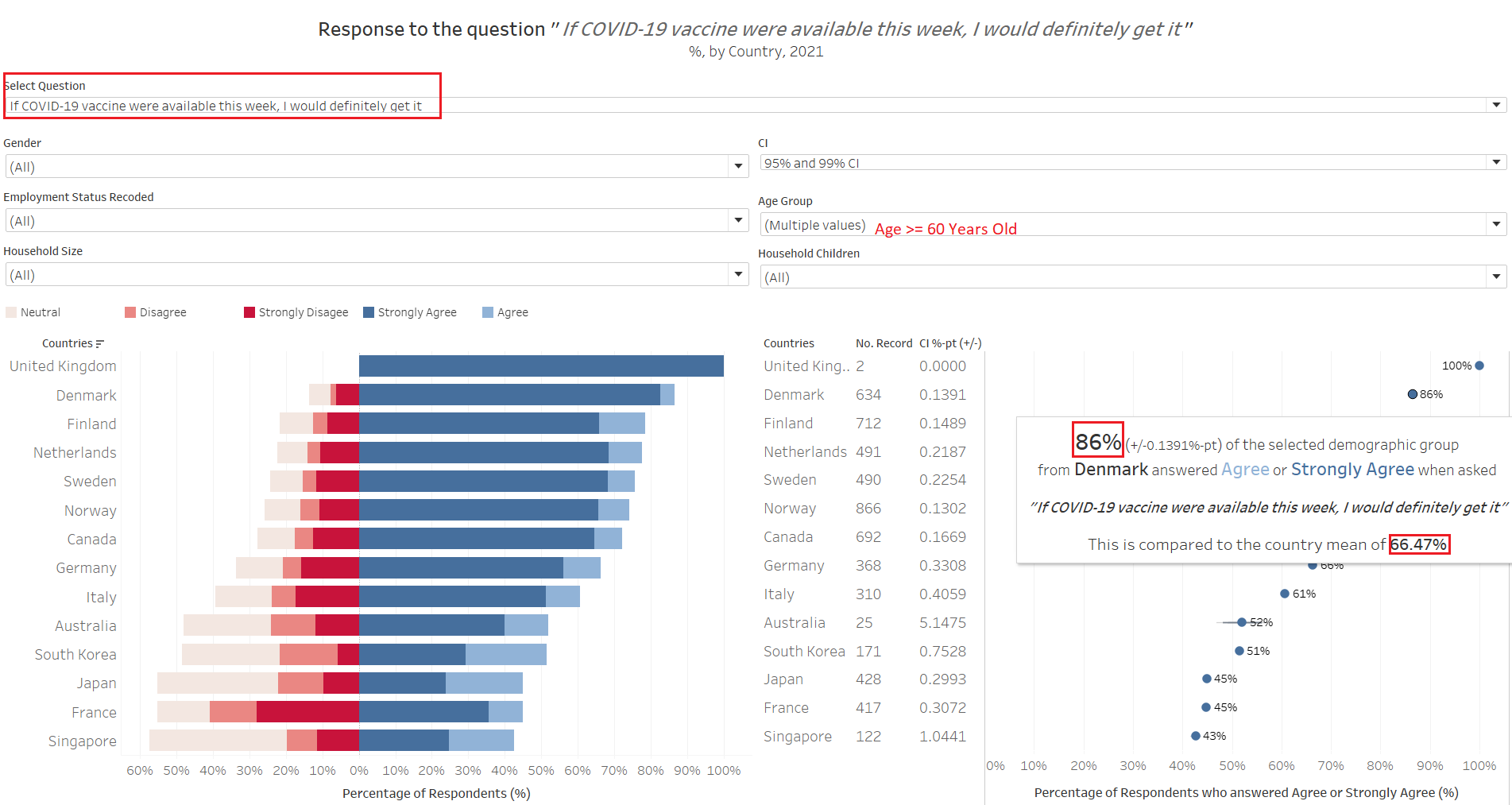
Indeed, household sizes and number of children, while affects the eagarness to get vaccinated, a larger underlying factor could be due to the fact that older respondents above the age of 60 are more eagar to get vaccinated and many of these older respondents interviewed happened to be living in smaller households without children. So while at the first glance it appears as if smaller households without children are more eagar for vaccination, as we saw with the younger group of small-household-without-children, they are no more keen to take vaccination than the general masses, and a more appropriate title for this observation should be “older respondents above the age of 60 are more eagar to get vaccinated”. This brings out an interesting point - what may appear to be the truth may not depict the full picture (even though it is not lying)!
Observation 3 - Retirees are more pro-vaccination than other employment status, and males more than female
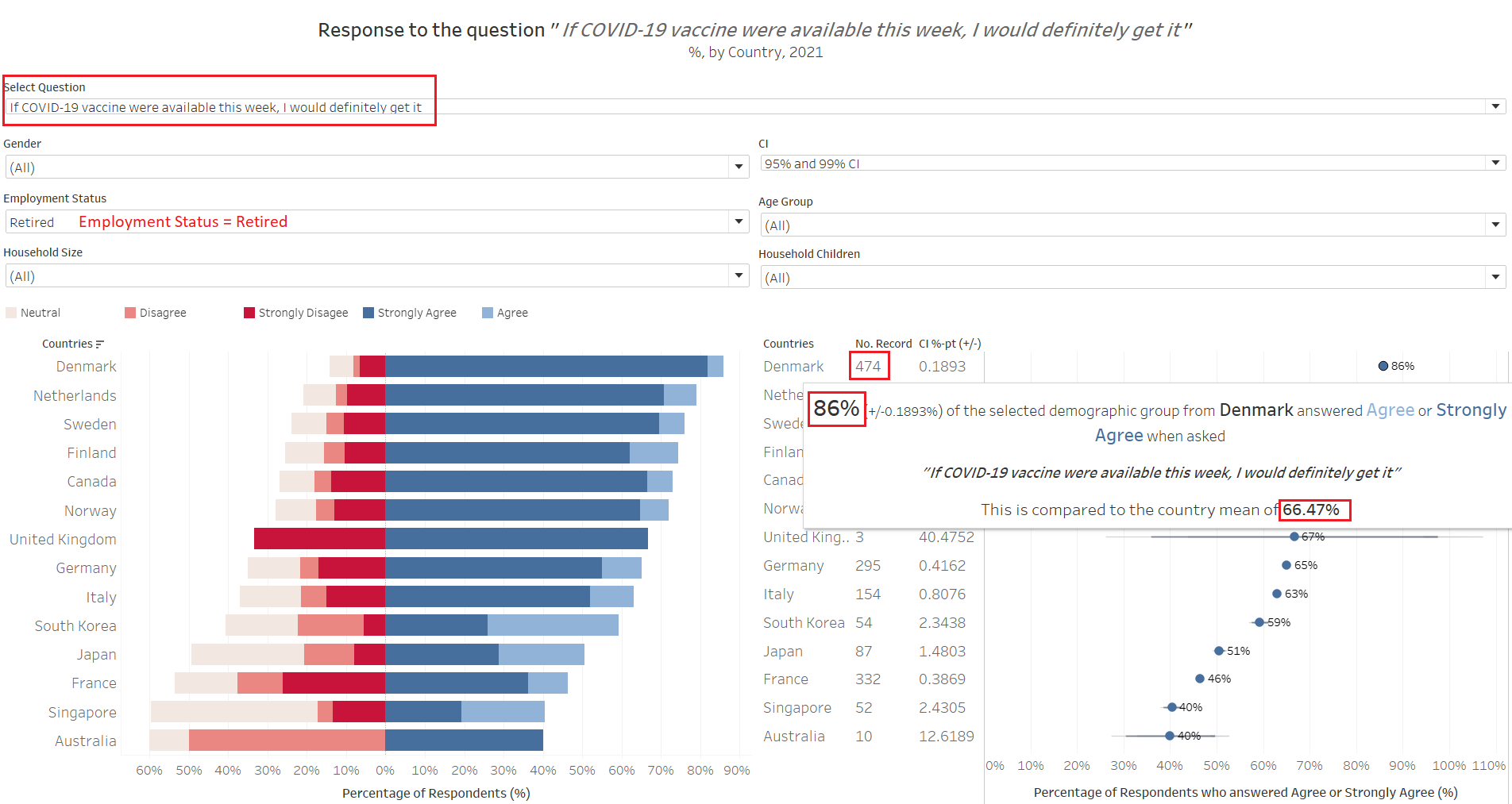
In a somewhat parallel comparison, we noted that the results are rather consistent when we narrow down to look at the response from “Retirees” across the countries. Looking at Denmark for example, the 86% pro-vaccination proportion coincides with the proportion for those older respondents above age 60 that we see above (although the number of records are small now, with about 160 older respondents who are not retired yet). This is similarly observed throughout the countries. When we look at every other groups by employment status, they are mostly less pro-vaccination than the country’s mean (again, this is due to the retirees pulling their weight in the response count).
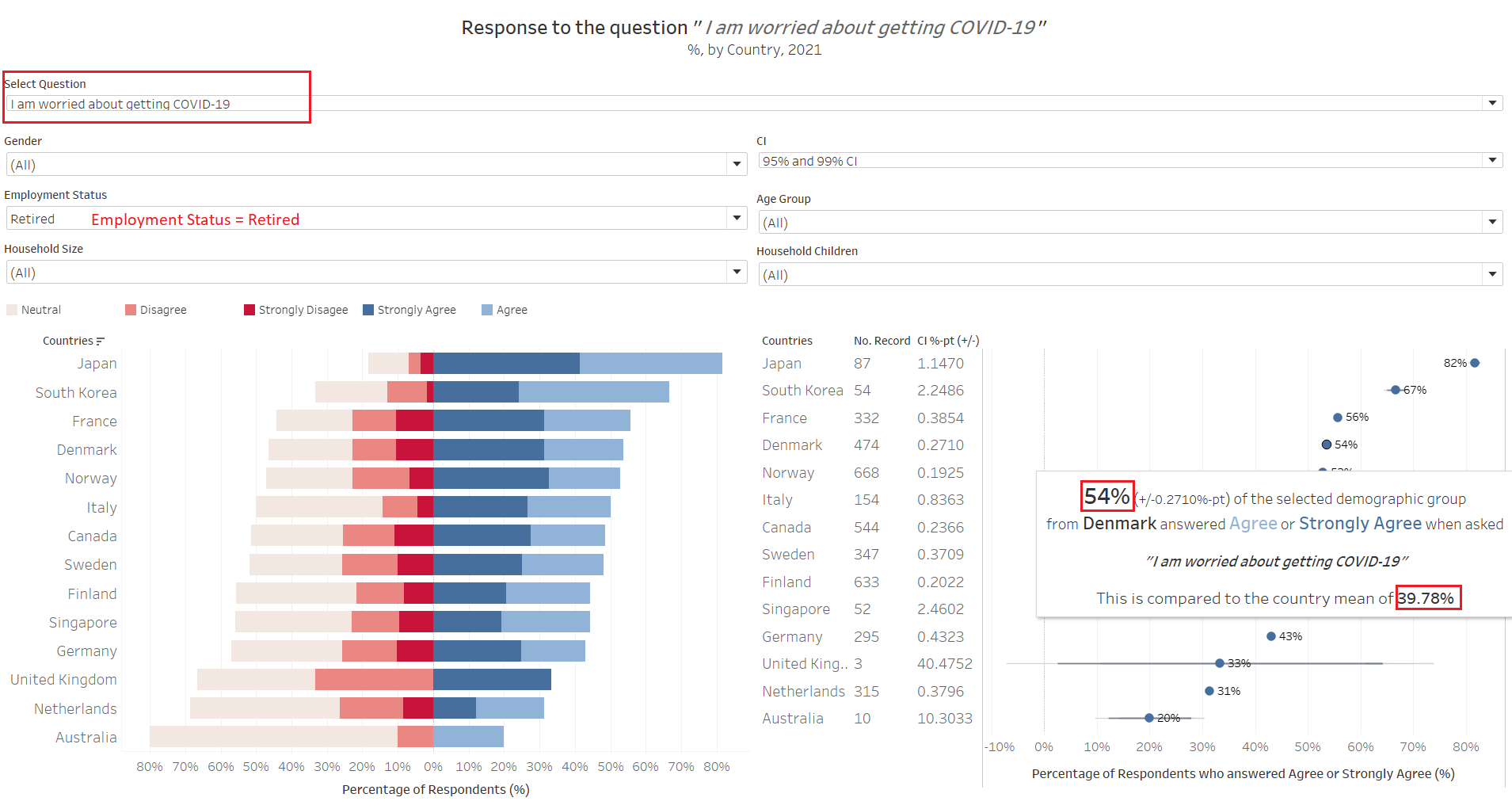
Nor surprisingly, this group also are must more worried about the virus than the general masses. However, only a smaller proportion are worried (e.g. Denmark’s 54%) as compared to those who would get vaccinated if available now (86%) - that is, many would get vaccinated, despite not being worried.
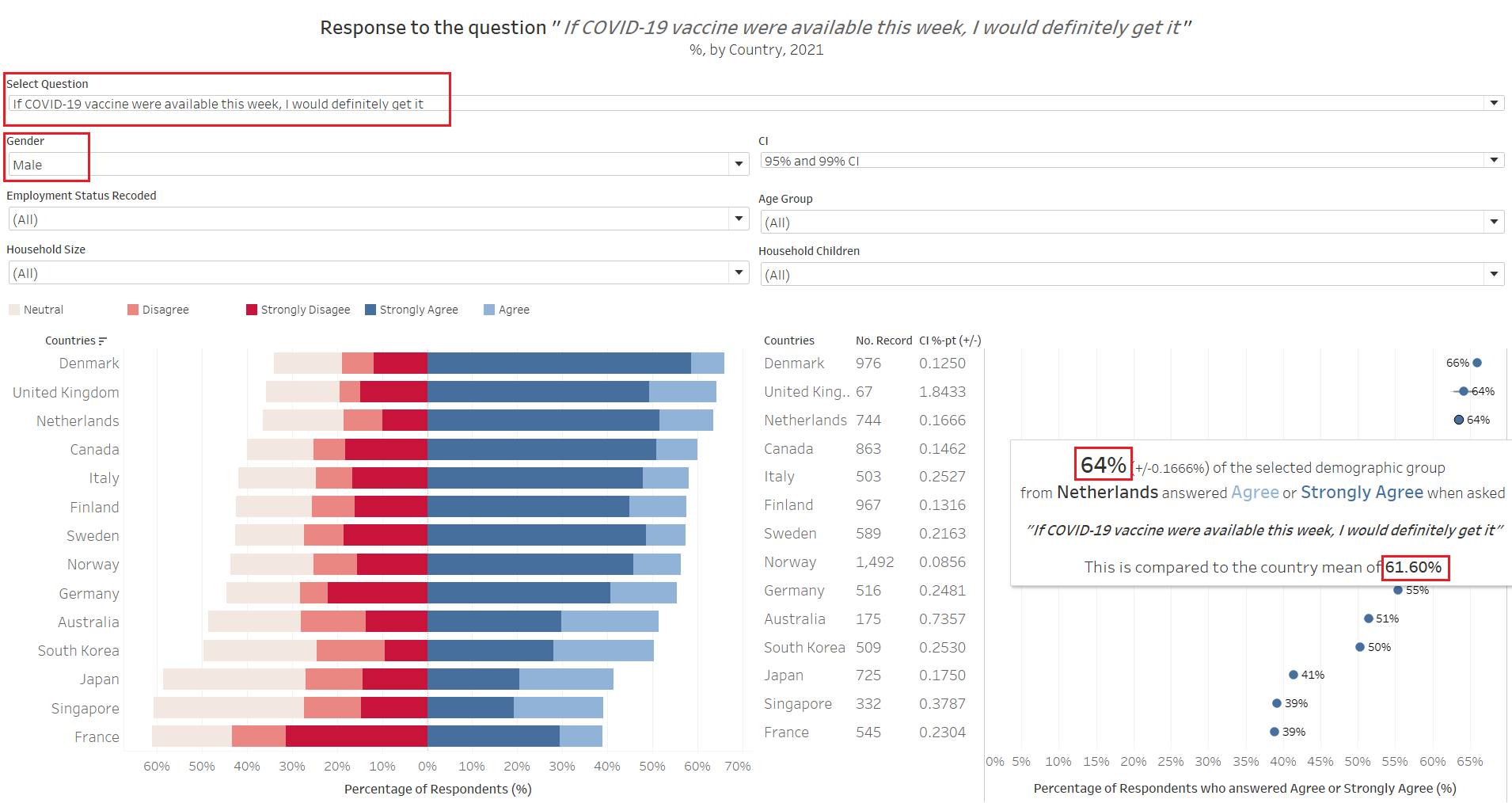
Next we switch to look at the split between males and females: in general, males are typically slightly more pro-vaccine than their female counterparts (except in Sweden).
Putting them altogether, we can conclude that retired males above 60 years old without kids in their small 1-2 pax households are the most pro-vaccination sub-group.
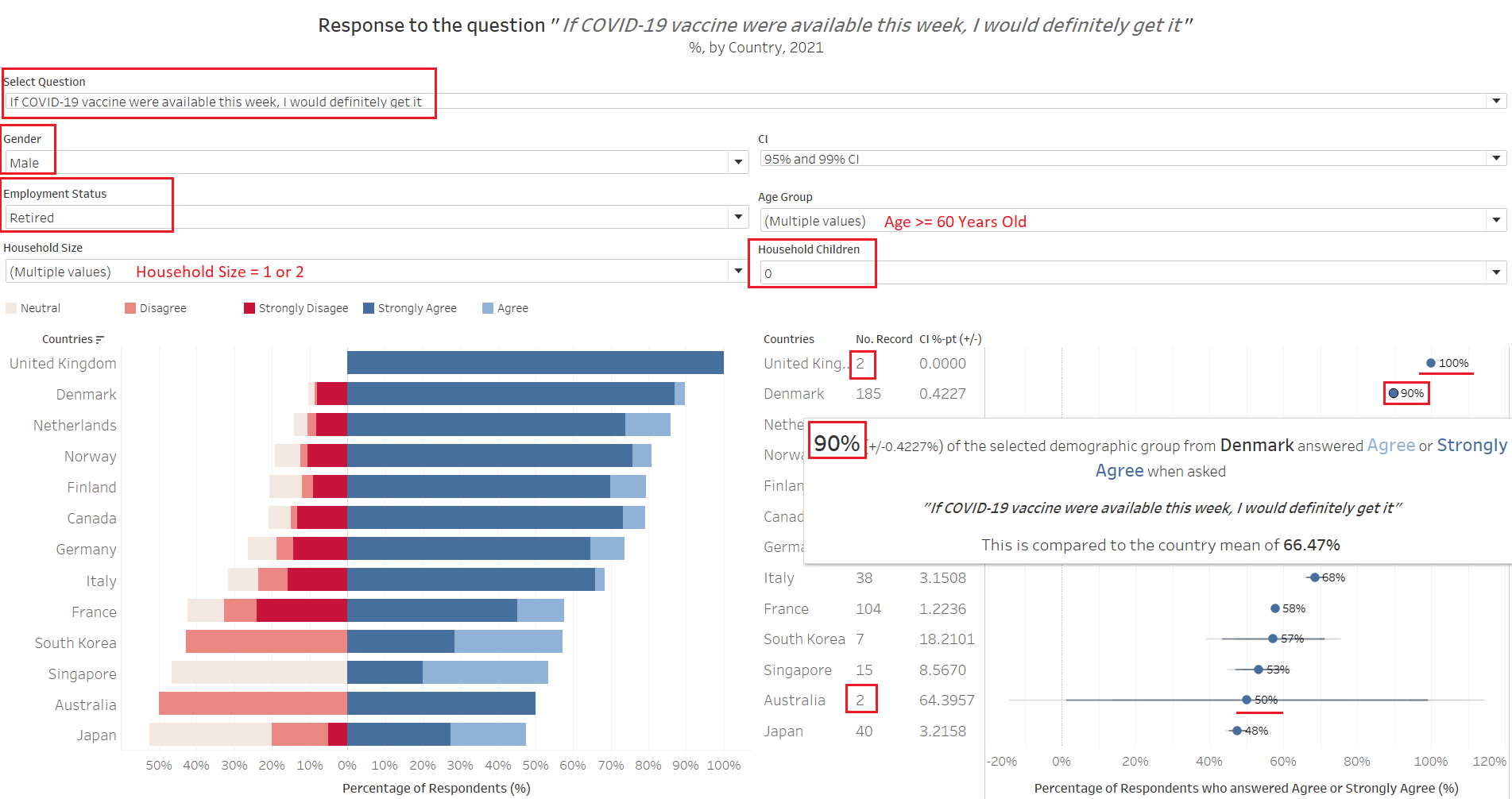
This proportion goes up to as high as 90% in Denmark. Why not mention the 100% with UK that does not seem to have any uncertainty? With 2 similar records, the formula is unable to derive a meaninful uncertainty (no “deviation” at all!); looking at Australia, when you have a “perfect deviation”, things turned hay-wire - and this is why it is important to present uncertainty along with the main estimated proportions.
Additional Comments
While the dataset provided a rich amount of information via the visualization done up, there are inherent biases and missing information present in the data.
Firstly, there is an obvious missing of countries from certain regions, and a total disregard for the fact that these countries are well-to-do advanced economies. This could be due to a lack of data, but would be interesting to find out how well-perceived are the vaccines in other parts of the world in geographical and socio-economic terms.
Secondly, given that vaccines are more readily-available in many countries today (and increasingly so), it would be intersting to see how the sentiment shifts with the greater prevalence of the vaccine (for further study, perhaps a time series plot of the response could be explored).
And lastly, an inherent issue with the existing data: having a larger proportion of older respondent.This will need to be addressed in order to prevent skewing of data by the opinion of a particular sub-population